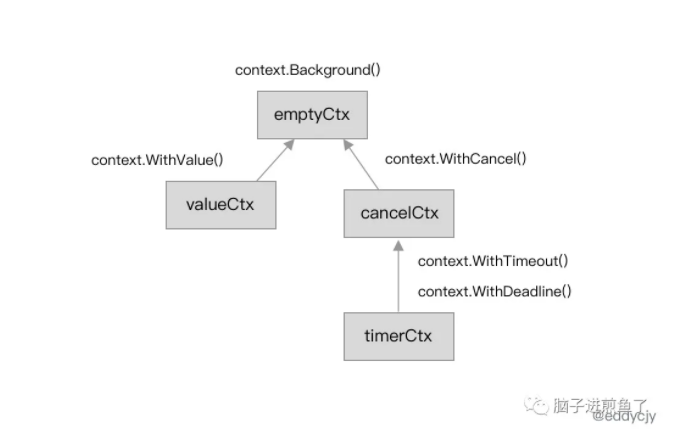
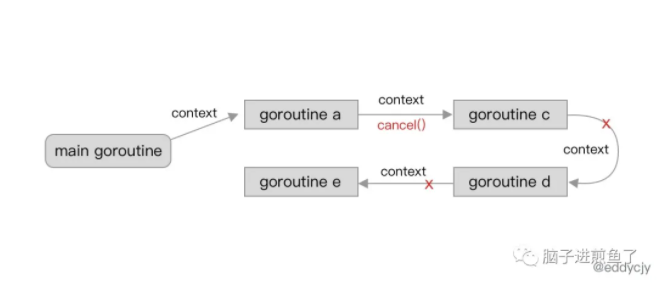
// A cancelCtx can be canceled. When canceled, it also cancels any children // that implement canceler. type cancelCtx struct { Context
mu sync.Mutex // protects following fields done chanstruct{} // created lazily, closed by first cancel call children map[canceler]struct{} // set to nil by the first cancel call err error// set to non-nil by the first cancel call }
func(c *cancelCtx) Value(key interface{}) interface{} { if key == &cancelCtxKey { return c } return c.Context.Value(key) }
func(c *cancelCtx) Done() <-chanstruct{} { c.mu.Lock() if c.done == nil { c.done = make(chanstruct{}) } d := c.done c.mu.Unlock() return d }
// A timerCtx carries a timer and a deadline. It embeds a cancelCtx to // implement Done and Err. It implements cancel by stopping its timer then // delegating to cancelCtx.cancel. type timerCtx struct { cancelCtx timer *time.Timer // Under cancelCtx.mu.
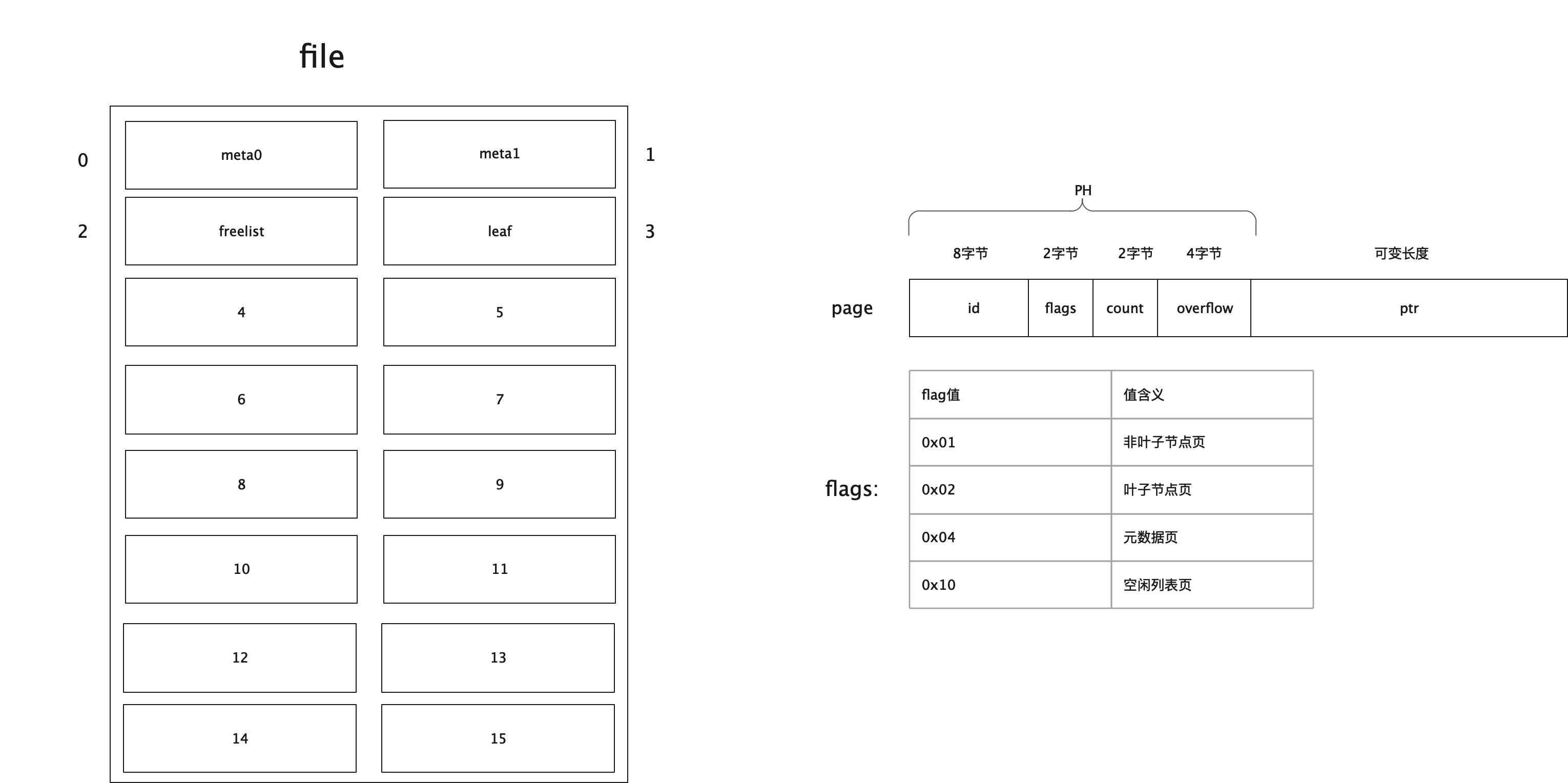
// DB represents a collection of buckets persisted to a file on disk. // All data access is performed through transactions which can be obtained through the DB. // All the functions on DB will return a ErrDatabaseNotOpen if accessed before Open() is called. type DB struct { path string file *os.File // 真实存储数据的磁盘文件 lockfile *os.File // windows only dataref []byte// mmap'ed readonly, write throws SEGV // 通过mmap映射进来的地址 data *[maxMapSize]byte datasz int filesz int// current on disk file size // 元数据 meta0 *meta meta1 *meta }
// 幂等 // The maximum batch size and delay can be adjusted with DB.MaxBatchSize // and DB.MaxBatchDelay, respectively. // // Batch is only useful when there are multiple goroutines calling it. func(db *DB) Batch(fn func(*Tx)error) error { errCh := make(chanerror, 1) db.batchMu.Lock() if (db.batch == nil) || (db.batch != nil && len(db.batch.calls) >= db.MaxBatchSize) { // There is no existing batch, or the existing batch is full; start a new one. db.batch = &batch{ db: db, } // 超时控制 db.batch.timer = time.AfterFunc(db.MaxBatchDelay, db.batch.trigger) } db.batch.calls = append(db.batch.calls, call{fn: fn, err: errCh}) // 数量控制 iflen(db.batch.calls) >= db.MaxBatchSize { // wake up batch, it's ready to run go db.batch.trigger() } db.batchMu.Unlock() err := <-errCh if err == trySolo { err = db.Update(fn) } return err }
// run performs the transactions in the batch and communicates results // back to DB.Batch. func(b *batch) run() { b.db.batchMu.Lock() b.timer.Stop() // Make sure no new work is added to this batch, but don't break // other batches. if b.db.batch == b { b.db.batch = nil } b.db.batchMu.Unlock()
retry: forlen(b.calls) > 0 { var failIdx = -1 err := b.db.Update(func(tx *Tx)error { // 遍历函数函数调用 for i, c := range b.calls { if err := safelyCall(c.fn, tx); err != nil { failIdx = i return err } } returnnil })
if failIdx >= 0 { // take the failing transaction out of the batch. it's // safe to shorten b.calls here because db.batch no longer // points to us, and we hold the mutex anyway. c := b.calls[failIdx] b.calls[failIdx], b.calls = b.calls[len(b.calls)-1], b.calls[:len(b.calls)-1] // tell the submitter re-run it solo, continue with the rest of the batch c.err <- trySolo continue retry }
// pass success, or bolt internal errors, to all callers // 失败的单独重试一次 for _, c := range b.calls { c.err <- err } break retry } }
// allocate returns a contiguous block of memory starting at a given page. func(db *DB) allocate(count int) (*page, error) { // Allocate a temporary buffer for the page. var buf []byte if count == 1 { buf = db.pagePool.Get().([]byte) } else { buf = make([]byte, count*db.pageSize) } // 转成*page p := (*page)(unsafe.Pointer(&buf[0])) p.overflow = uint32(count - 1) // Use pages from the freelist if they are available. // 先从空闲列表中找 if p.id = db.freelist.allocate(count); p.id != 0 { return p, nil } // 找不到的话,就按照事务的pgid来分配 // 表示需要从文件内部扩大 // Resize mmap() if we're at the end. p.id = db.rwtx.meta.pgid // 因此需要判断是否目前所有的页数已经大于了mmap映射出来的空间 // 这儿计算的页面总数是从当前的id后还要计算count+1个 var minsz = int((p.id+pgid(count))+1) * db.pageSize if minsz >= db.datasz { if err := db.mmap(minsz); err != nil { returnnil, fmt.Errorf("mmap allocate error: %s", err) } } // Move the page id high water mark. // 如果不是从freelist中找到的空间的话,更新meta的id,也就意味着是从文件中新扩展的页 db.rwtx.meta.pgid += pgid(count) return p, nil } // grow grows the size of the database to the given sz. func(db *DB) grow(sz int) error { // Ignore if the new size is less than available file size. if sz <= db.filesz { returnnil } // 满足这个条件sz>filesz // If the data is smaller than the alloc size then only allocate what's needed. // Once it goes over the allocation size then allocate in chunks. if db.datasz < db.AllocSize { sz = db.datasz } else { sz += db.AllocSize } // Truncate and fsync to ensure file size metadata is flushed. // https://github.com/boltdb/bolt/issues/284 if !db.NoGrowSync && !db.readOnly { if runtime.GOOS != "windows" { if err := db.file.Truncate(int64(sz)); err != nil { return fmt.Errorf("file resize error: %s", err) } } if err := db.file.Sync(); err != nil { return fmt.Errorf("file sync error: %s", err) } } db.filesz = sz returnnil }
// allocate returns a contiguous block of memory starting at a given page. func(db *DB) allocate(count int) (*page, error) { // Allocate a temporary buffer for the page. var buf []byte if count == 1 { buf = db.pagePool.Get().([]byte) } else { buf = make([]byte, count*db.pageSize) } // 转成*page p := (*page)(unsafe.Pointer(&buf[0])) p.overflow = uint32(count - 1) // Use pages from the freelist if they are available. // 先从空闲列表中找 if p.id = db.freelist.allocate(count); p.id != 0 { return p, nil } // 找不到的话,就按照事务的pgid来分配 // 表示需要从文件内部扩大 // Resize mmap() if we're at the end. p.id = db.rwtx.meta.pgid // 因此需要判断是否目前所有的页数已经大于了mmap映射出来的空间 // 这儿计算的页面总数是从当前的id后还要计算count+1个 var minsz = int((p.id+pgid(count))+1) * db.pageSize if minsz >= db.datasz { if err := db.mmap(minsz); err != nil { returnnil, fmt.Errorf("mmap allocate error: %s", err) } } // Move the page id high water mark. // 如果不是从freelist中找到的空间的话,更新meta的id,也就意味着是从文件中新扩展的页 db.rwtx.meta.pgid += pgid(count) return p, nil } // grow grows the size of the database to the given sz. func(db *DB) grow(sz int) error { // Ignore if the new size is less than available file size. if sz <= db.filesz { returnnil } // 满足这个条件sz>filesz // If the data is smaller than the alloc size then only allocate what's needed. // Once it goes over the allocation size then allocate in chunks. if db.datasz < db.AllocSize { sz = db.datasz } else { sz += db.AllocSize } // Truncate and fsync to ensure file size metadata is flushed. // https://github.com/boltdb/bolt/issues/284 if !db.NoGrowSync && !db.readOnly { if runtime.GOOS != "windows" { if err := db.file.Truncate(int64(sz)); err != nil { return fmt.Errorf("file resize error: %s", err) } } if err := db.file.Sync(); err != nil { return fmt.Errorf("file sync error: %s", err) } } db.filesz = sz returnnil }
Bolt is a pure Go key/value store inspired by [Howard Chu’s][hyc_symas] [LMDB project][lmdb]. The goal of the project is to provide a simple, fast, and reliable database for projects that don’t require a full database server such as Postgres or MySQL.
Since Bolt is meant to be used as such a low-level piece of functionality, simplicity is key. The API will be small and only focus on getting values and setting values. That’s it.
// Bucket represents a collection of key/value pairs inside the database. type Bucket struct { *bucket tx *Tx // the associated transaction buckets map[string]*Bucket // subbucket cache page *page // inline page reference rootNode *node // materialized node for the root page. nodes map[pgid]*node // node cache
// Sets the threshold for filling nodes when they split. By default, // the bucket will fill to 50% but it can be useful to increase this // amount if you know that your write workloads are mostly append-only. // // This is non-persisted across transactions so it must be set in every Tx. FillPercent float64 }
// bucket represents the on-file representation of a bucket. // This is stored as the "value" of a bucket key. If the bucket is small enough, // then its root page can be stored inline in the "value", after the bucket // header. In the case of inline buckets, the "root" will be 0. type bucket struct { root pgid // page id of the bucket's root-level page sequence uint64// monotonically incrementing, used by NextSequence() }
// Cursor creates a cursor associated with the bucket. // The cursor is only valid as long as the transaction is open. // Do not use a cursor after the transaction is closed. func(b *Bucket) Cursor() *Cursor { // Update transaction statistics. b.tx.stats.CursorCount++
// Allocate and return a cursor. return &Cursor{ bucket: b, stack: make([]elemRef, 0), } }
// elemRef represents a reference to an element on a given page/node. type elemRef struct { page *page node *node index int }
// isLeaf returns whether the ref is pointing at a leaf page/node. func(r *elemRef) isLeaf() bool { if r.node != nil { return r.node.isLeaf } return (r.page.flags & leafPageFlag) != 0 }
// count returns the number of inodes or page elements. func(r *elemRef) count() int { if r.node != nil { returnlen(r.node.inodes) } returnint(r.page.count) }
Cursor结构
1 2 3 4 5 6 7 8 9
type Cursor struct { bucket *Bucket stack []elemRef }
// Bucket returns the bucket that this cursor was created from. func(c *Cursor) Bucket() *Bucket { return c.bucket }
func(c *Cursor) First() (key []byte, value []byte)
func(c *Cursor) Last() (key []byte, value []byte)
func(c *Cursor) Next() (key []byte, value []byte)
func(c *Cursor) Prev() (key []byte, value []byte)
func(c *Cursor) Delete() error // Seek moves the cursor to a given key and returns it. // If the key does not exist then the next key is used. If no keys // follow, a nil key is returned. // The returned key and value are only valid for the life of the transaction. func(c *Cursor) Seek(seek []byte) (key []byte, value []byte)
// pageNode returns the in-memory node, if it exists. // Otherwise returns the underlying page. func(b *Bucket) pageNode(id pgid) (*page, *node) { // Inline buckets have a fake page embedded in their value so treat them // differently. We'll return the rootNode (if available) or the fake page. if b.root == 0 { if id != 0 { panic(fmt.Sprintf("inline bucket non-zero page access(2): %d != 0", id)) } if b.rootNode != nil { returnnil, b.rootNode } return b.page, nil }
// Check the node cache for non-inline buckets. if b.nodes != nil { if n := b.nodes[id]; n != nil { returnnil, n } }
// Finally lookup the page from the transaction if no node is materialized. return b.tx.page(id), nil }
// data 表示 mmap 的 file 数据 // page retrieves a page reference from the mmap based on the current page size. func(db *DB) page(id pgid) *page { pos := id * pgid(db.pageSize) return (*page)(unsafe.Pointer(&db.data[pos])) }
func(c *Cursor) Seek(seek []byte) (key []byte, value []byte) { k, v, flags := c.seek(seek) // If we ended up after the last element of a page then move to the next one. // 下面这一段逻辑是必须的,因为在seek()方法中,如果ref.index>ref.count()的话,就直接返回nil,nil,0了 // 这里需要返回下一个 if ref := &c.stack[len(c.stack)-1]; ref.index >= ref.count() { k, v, flags = c.next() } if k == nil { returnnil, nil // 子桶的话 } elseif (flags & uint32(bucketLeafFlag)) != 0 { return k, nil } return k, v }
// 实际上调用 search 方法 func(c *Cursor) seek(seek []byte) (key []byte, value []byte, flags uint32) { // Start from root page/node and traverse to correct page. c.stack = c.stack[:0] c.search(seek, c.bucket.root)
// If this is a bucket then return a nil value. return c.keyValue() }
// 整个 search 就是构建了一个搜索栈,最后用 elemRef 中的 index, 这个 index 表示node 中 inodes 的下标,或者 page 下标。 // search recursively performs a binary search against a given page/node until it finds a given key. func(c *Cursor) search(key []byte, pgid pgid) { p, n := c.bucket.pageNode(pgid) if p != nil && (p.flags&(branchPageFlag|leafPageFlag)) == 0 { panic(fmt.Sprintf("invalid page type: %d: %x", p.id, p.flags)) } e := elemRef{page: p, node: n} // 搜索栈 c.stack = append(c.stack, e)
// If we're on a leaf page/node then find the specific node. // 叶子结点就直接最后一次二分查询了 if e.isLeaf() { c.nsearch(key) return }
func(c *Cursor) searchNode(key []byte, n *node) { var exact bool index := sort.Search(len(n.inodes), func(i int)bool { // TODO(benbjohnson): Optimize this range search. It's a bit hacky right now. // sort.Search() finds the lowest index where f() != -1 but we need the highest index. ret := bytes.Compare(n.inodes[i].key, key) if ret == 0 { exact = true } return ret != -1 }) if !exact && index > 0 { index-- } c.stack[len(c.stack)-1].index = index
// Recursively search to the next page. c.search(key, n.inodes[index].pgid) }
// keyValue returns the key and value of the current leaf element. func(c *Cursor) keyValue() ([]byte, []byte, uint32) { ref := &c.stack[len(c.stack)-1]
// If the cursor is pointing to the end of page/node then return nil. if ref.count() == 0 || ref.index >= ref.count() { returnnil, nil, 0 }
// Retrieve value from node. if ref.node != nil { inode := &ref.node.inodes[ref.index] return inode.key, inode.value, inode.flags }
// Or retrieve value from page. elem := ref.page.leafPageElement(uint16(ref.index)) return elem.key(), elem.value(), elem.flags }
func(c *Cursor) First() (key []byte, value []byte) { _assert(c.bucket.tx.db != nil, "tx closed") // 清空stack c.stack = c.stack[:0] p, n := c.bucket.pageNode(c.bucket.root) // 一直找到第一个叶子节点,此处在天添加stack时,一直让index设置为0即可 ref := elemRef{page: p, node: n, index: 0} c.stack = append(c.stack, ref) c.first() // If we land on an empty page then move to the next value. // https://github.com/boltdb/bolt/issues/450 // 当前页时空的话,找下一个 if c.stack[len(c.stack)-1].count() == 0 { c.next() } k, v, flags := c.keyValue() // 是桶 if (flags & uint32(bucketLeafFlag)) != 0 { return k, nil } return k, v } // first moves the cursor to the first leaf element under the last page in the stack. // 找到最后一个非叶子节点的第一个叶子节点。index=0的节点 func(c *Cursor) first() { for { // Exit when we hit a leaf page. var ref = &c.stack[len(c.stack)-1] if ref.isLeaf() { break } // Keep adding pages pointing to the first element to the stack. var pgid pgid if ref.node != nil { pgid = ref.node.inodes[ref.index].pgid } else { pgid = ref.page.branchPageElement(uint16(ref.index)).pgid } p, n := c.bucket.pageNode(pgid) c.stack = append(c.stack, elemRef{page: p, node: n, index: 0}) } }
Next 分析
使用方式
1 2 3 4 5 6
c := b.Cursor()
// 启动遍历模式 for k, v := c.First(); k != nil; k, v = c.Next() { fmt.Printf("cursor, key=%s, value=%s\n", string(k), string(v)) }
// next 的实现就是去移动每一个 node 的 index, 从叶子结点开始,这样就能遍历完所有的叶子结点了!!! // next moves to the next leaf element and returns the key and value. // If the cursor is at the last leaf element then it stays there and returns nil. func(c *Cursor) next() (key []byte, value []byte, flags uint32) { for { // Attempt to move over one element until we're successful. // Move up the stack as we hit the end of each page in our stack. var i int // c.stack 是在调用 First 函数时被写入的,所以,这样倒序来遍历能实现按序获取 for i = len(c.stack) - 1; i >= 0; i-- { elem := &c.stack[i] if elem.index < elem.count()-1 { elem.index++ break } }
// If we've hit the root page then stop and return. This will leave the // cursor on the last element of the last page. if i == -1 { returnnil, nil, 0 }
// Otherwise start from where we left off in the stack and find the // first element of the first leaf page. c.stack = c.stack[:i+1] // 获取下一个叶子结点 c.first()
// If this is an empty page then restart and move back up the stack. // https://github.com/boltdb/bolt/issues/450 if c.stack[len(c.stack)-1].count() == 0 { continue }
/ inode represents an internal node inside of a node. // It can be used to point to elements in a page or point // to an element which hasn't been added to a page yet. type inode struct { // 表示是否是子桶叶子节点还是普通叶子节点。如果flags值为1表示子桶叶子节点,否则为普通叶子节点 flags uint32 // 当inode为分支元素时,pgid才有值,为叶子元素时,则没值 pgid pgid key []byte // 当inode为分支元素时,value为空,为叶子元素时,才有值 value []byte }
// Add capacity and shift nodes if we don't have an exact match and need to insert. exact := (len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey)) if !exact { n.inodes = append(n.inodes, inode{}) copy(n.inodes[index+1:], n.inodes[index:]) }
// del removes a key from the node. func(n *node) del(key []byte) { // Find index of key. index := sort.Search(len(n.inodes), func(i int)bool { return bytes.Compare(n.inodes[i].key, key) != -1 })
// Exit if the key isn't found. if index >= len(n.inodes) || !bytes.Equal(n.inodes[index].key, key) { return }
// Delete inode from the node. n.inodes = append(n.inodes[:index], n.inodes[index+1:]...)
// Mark the node as needing rebalancing. n.unbalanced = true }
// childAt returns the child node at a given index. func(n *node) childAt(index int) *node { if n.isLeaf { panic(fmt.Sprintf("invalid childAt(%d) on a leaf node", index)) } return n.bucket.node(n.inodes[index].pgid, n) }
// childIndex returns the index of a given child node. func(n *node) childIndex(child *node) int { index := sort.Search(len(n.inodes), func(i int)bool { return bytes.Compare(n.inodes[i].key, child.key) != -1 }) return index }
// numChildren returns the number of children. func(n *node) numChildren() int { returnlen(n.inodes) }
// nextSibling returns the next node with the same parent. func(n *node) nextSibling() *node { if n.parent == nil { returnnil } // 有父节点问题就不大了 index := n.parent.childIndex(n) if index >= n.parent.numChildren()-1 { returnnil } return n.parent.childAt(index + 1) }
// prevSibling returns the previous node with the same parent. func(n *node) prevSibling() *node { if n.parent == nil { returnnil } index := n.parent.childIndex(n) if index == 0 { returnnil } return n.parent.childAt(index - 1) }
// CreateBucket creates a new bucket at the given key and returns the new bucket. // Returns an error if the key already exists, if the bucket name is blank, or if the bucket name is too long. // The bucket instance is only valid for the lifetime of the transaction. func(b *Bucket) CreateBucket(key []byte) (*Bucket, error) { if b.tx.db == nil { returnnil, ErrTxClosed } elseif !b.tx.writable { returnnil, ErrTxNotWritable } elseiflen(key) == 0 { returnnil, ErrBucketNameRequired } // Move cursor to correct position. // 拿到游标 c := b.Cursor() // 开始遍历、找到合适的位置 k, _, flags := c.seek(key) // Return an error if there is an existing key. if bytes.Equal(key, k) { // 是桶,已经存在了 if (flags & bucketLeafFlag) != 0 { returnnil, ErrBucketExists } // 不是桶、但key已经存在了 returnnil, ErrIncompatibleValue } // Create empty, inline bucket. var bucket = Bucket{ bucket: &bucket{}, rootNode: &node{isLeaf: true}, FillPercent: DefaultFillPercent, } // 拿到bucket对应的value var value = bucket.write() // Insert into node. key = cloneBytes(key) // 插入到inode中 // c.node()方法会在内存中建立这棵树,调用n.read(page) c.node().put(key, key, value, 0, bucketLeafFlag) // Since subbuckets are not allowed on inline buckets, we need to // dereference the inline page, if it exists. This will cause the bucket // to be treated as a regular, non-inline bucket for the rest of the tx. b.page = nil //根据key获取一个桶 return b.Bucket(key), nil }
/ Bucket retrieves a nested bucket by name. // Returns nil if the bucket does not exist. // The bucket instance is only valid for the lifetime of the transaction. func(b *Bucket) Bucket(name []byte) *Bucket { if b.buckets != nil { if child := b.buckets[string(name)]; child != nil { return child } } // Move cursor to key. // 根据游标找key c := b.Cursor() k, v, flags := c.seek(name) // Return nil if the key doesn't exist or it is not a bucket. if !bytes.Equal(name, k) || (flags&bucketLeafFlag) == 0 { returnnil } // Otherwise create a bucket and cache it. // 根据找到的value来打开桶。 var child = b.openBucket(v) // 加速缓存的作用 if b.buckets != nil { b.buckets[string(name)] = child } return child } // Helper method that re-interprets a sub-bucket value // from a parent into a Bucket func(b *Bucket) openBucket(value []byte) *Bucket { var child = newBucket(b.tx) // If unaligned load/stores are broken on this arch and value is // unaligned simply clone to an aligned byte array. unaligned := brokenUnaligned && uintptr(unsafe.Pointer(&value[0]))&3 != 0 if unaligned { value = cloneBytes(value) } // If this is a writable transaction then we need to copy the bucket entry. // Read-only transactions can point directly at the mmap entry. if b.tx.writable && !unaligned { child.bucket = &bucket{} *child.bucket = *(*bucket)(unsafe.Pointer(&value[0])) } else { child.bucket = (*bucket)(unsafe.Pointer(&value[0])) } // Save a reference to the inline page if the bucket is inline. // 内联桶 if child.root == 0 { child.page = (*page)(unsafe.Pointer(&value[bucketHeaderSize])) } return &child }
// Return nil if this is a bucket. if (flags & bucketLeafFlag) != 0 { returnnil }
// If our target node isn't the same key as what's passed in then return nil. if !bytes.Equal(key, k) { returnnil } return v }
func(b *Bucket) Put(key []byte, value []byte) error { // Move cursor to correct position. c := b.Cursor() k, _, flags := c.seek(key)
// Return an error if there is an existing key with a bucket value. if bytes.Equal(key, k) && (flags&bucketLeafFlag) != 0 { return ErrIncompatibleValue }
// meta returns a pointer to the metadata section of the page. func(p *page) meta() *meta { return (*meta)(unsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p))) }
详细的元数据信息定义如下:
1 2 3 4 5 6 7 8 9 10 11
type meta struct { magic uint32//魔数 version uint32//版本 pageSize uint32//page页的大小,该值和操作系统默认的页大小保持一致 flags uint32//保留值,目前貌似还没用到 root bucket //所有小柜子bucket的根 freelist pgid //空闲列表页的id pgid pgid //元数据页的id txid txid //最大的事务id checksum uint64//用作校验的校验和 }
type freelist struct { // 已经可以被分配的空闲页 ids []pgid // all free and available free page ids. // 将来很快能被释放的空闲页,部分事务可能在读或者写 pending map[txid][]pgid // mapping of soon-to-be free page ids by tx. cache map[pgid]bool// fast lookup of all free and pending page ids. }
freelist->page
将空闲列表转换成页信息,写到磁盘中,此处需要注意一个问题.
1 2 3 4
// write writes the page ids onto a freelist page. All free and pending ids are // saved to disk since in the event of a program crash, all pending ids will // become free. func(f *freelist) write(p *page) error {}
// Stop here if there are no items to write. if p.count == 0 { return }
// Loop over each item and write it to the page. // off tracks the offset into p of the start of the next data. // off: page 和 page elements 的头信息 off := unsafe.Sizeof(*p) + n.pageElementSize()*uintptr(len(n.inodes)) for i, item := range n.inodes { _assert(len(item.key) > 0, "write: zero-length inode key")
// Create a slice to write into of needed size and advance // byte pointer for next iteration. sz := len(item.key) + len(item.value) b := unsafeByteSlice(unsafe.Pointer(p), off, 0, sz) off += uintptr(sz)
// Write the page element. // 1. 写一个节点的头信息 if n.isLeaf { elem := p.leafPageElement(uint16(i)) elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))) elem.flags = item.flags elem.ksize = uint32(len(item.key)) elem.vsize = uint32(len(item.value)) } else { elem := p.branchPageElement(uint16(i)) elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))) elem.ksize = uint32(len(item.key)) elem.pgid = item.pgid _assert(elem.pgid != p.id, "write: circular dependency occurred") } // 2. 写数据信息 // Write data for the element to the end of the page. l := copy(b, item.key) copy(b[l:], item.value) }
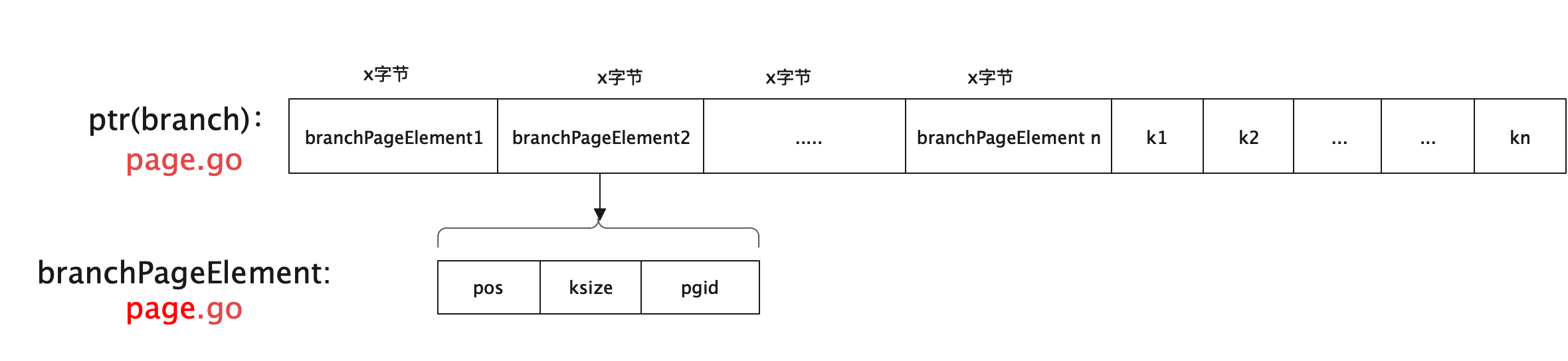
// leafPageElement represents a node on a leaf page. // 叶子节点既存储key,也存储value type leafPageElement struct { flags uint32//该值主要用来区分,是子桶叶子节点元素还是普通的key/value叶子节点元素。flags值为1时表示子桶。否则为key/value pos uint32 ksize uint32 vsize uint32 }
// key returns a byte slice of the node key. func(n *leafPageElement) key() []byte { i := int(n.pos) j := i + int(n.ksize) return unsafeByteSlice(unsafe.Pointer(n), 0, i, j) }
// value returns a byte slice of the node value. func(n *leafPageElement) value() []byte { i := int(n.pos) + int(n.ksize) j := i + int(n.vsize) return unsafeByteSlice(unsafe.Pointer(n), 0, i, j) }
// leafPageElement retrieves the leaf node by index func(p *page) leafPageElement(index uint16) *leafPageElement { return (*leafPageElement)(unsafeIndex(unsafe.Pointer(p), unsafe.Sizeof(*p), leafPageElementSize, int(index))) }
// leafPageElements retrieves a list of leaf nodes. func(p *page) leafPageElements() []leafPageElement { if p.count == 0 { returnnil } var elems []leafPageElement data := unsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p)) unsafeSlice(unsafe.Pointer(&elems), data, int(p.count)) return elems }
// Tx 主要封装了读事务和写事务。其中通过writable来区分是读事务还是写事务 type Tx struct { writable bool managed bool db *DB meta *meta root Bucket pages map[pgid]*page stats TxStats // 提交时执行的动作 commitHandlers []func()
// WriteFlag specifies the flag for write-related methods like WriteTo(). // Tx opens the database file with the specified flag to copy the data. // // By default, the flag is unset, which works well for mostly in-memory // workloads. For databases that are much larger than available RAM, // set the flag to syscall.O_DIRECT to avoid trashing the page cache. WriteFlag int }
// init initializes the transaction. func(tx *Tx) init(db *DB) { tx.db = db tx.pages = nil
// Copy the meta page since it can be changed by the writer. // 拷贝元信息 tx.meta = &meta{} db.meta().copy(tx.meta)
// Copy over the root bucket. // 拷贝根节点 tx.root = newBucket(tx) tx.root.bucket = &bucket{} // meta.root=bucket{root:3} *tx.root.bucket = tx.meta.root
// Increment the transaction id and add a page cache for writable transactions. if tx.writable { tx.pages = make(map[pgid]*page) tx.meta.txid += txid(1) } }
// WriteTo writes the entire database to a writer. // If err == nil then exactly tx.Size() bytes will be written into the writer. // 将当前 database 写入到 w func(tx *Tx) WriteTo(w io.Writer) (n int64, err error) {}
// 从一个地址开始将, 转为字节流 funcunsafeByteSlice(base unsafe.Pointer, offset uintptr, i, j int) []byte { // See: https://github.com/golang/go/wiki/cgo#turning-c-arrays-into-go-slices // // This memory is not allocated from C, but it is unmanaged by Go's // garbage collector and should behave similarly, and the compiler // should produce similar code. Note that this conversion allows a // subslice to begin after the base address, with an optional offset, // while the URL above does not cover this case and only slices from // index 0. However, the wiki never says that the address must be to // the beginning of a C allocation (or even that malloc was used at // all), so this is believed to be correct. return (*[maxAllocSize]byte)(unsafeAdd(base, offset))[i:j:j] }
// 修改 slice 的值域 // unsafeSlice modifies the data, len, and cap of a slice variable pointed to by // the slice parameter. This helper should be used over other direct // manipulation of reflect.SliceHeader to prevent misuse, namely, converting // from reflect.SliceHeader to a Go slice type. funcunsafeSlice(slice, data unsafe.Pointer, lenint) { s := (*reflect.SliceHeader)(slice) s.Data = uintptr(data) s.Cap = len s.Len = len }