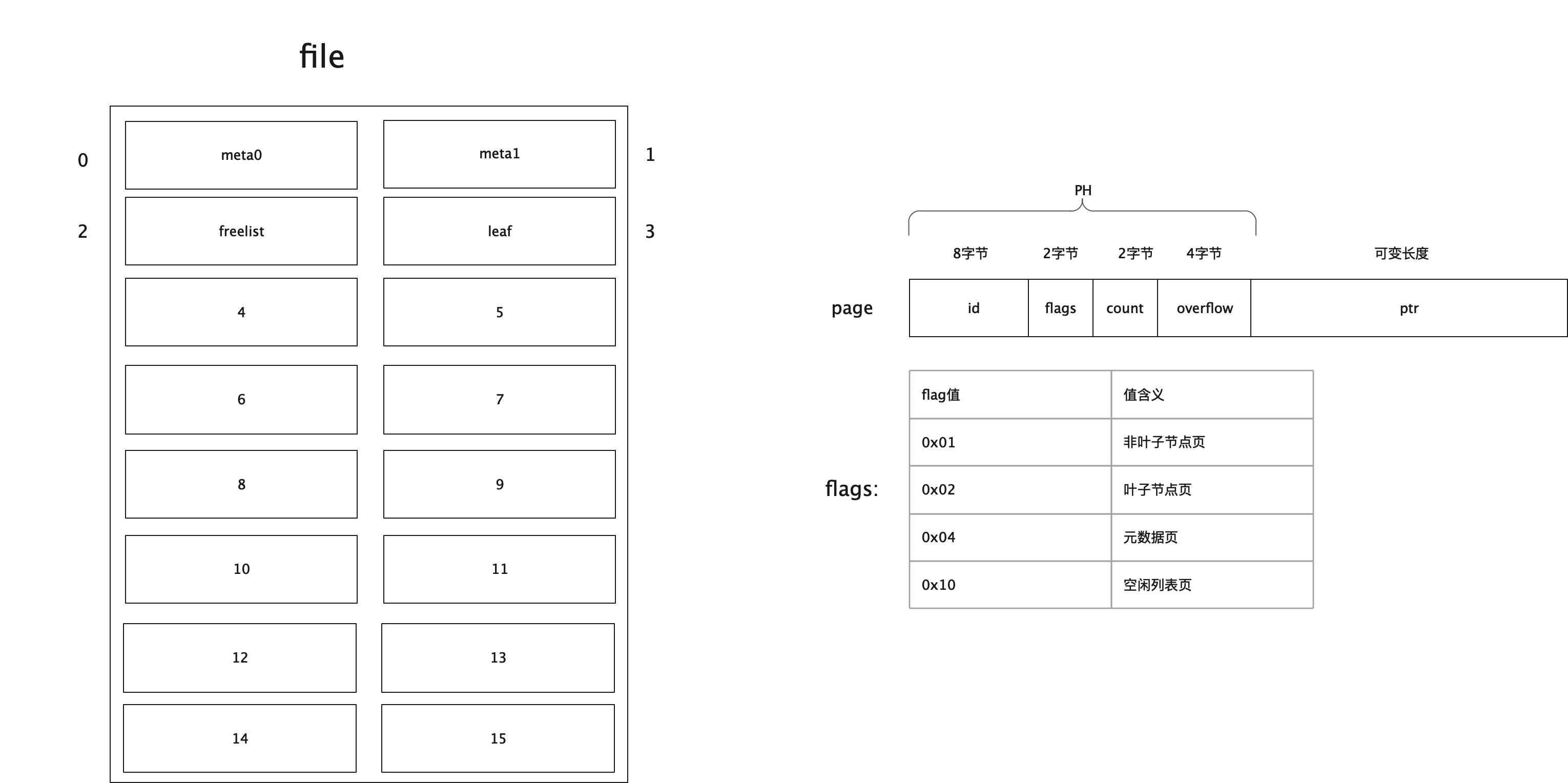
// meta returns a pointer to the metadata section of the page. func(p *page) meta() *meta { return (*meta)(unsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p))) }
详细的元数据信息定义如下:
1 2 3 4 5 6 7 8 9 10 11
type meta struct { magic uint32//魔数 version uint32//版本 pageSize uint32//page页的大小,该值和操作系统默认的页大小保持一致 flags uint32//保留值,目前貌似还没用到 root bucket //所有小柜子bucket的根 freelist pgid //空闲列表页的id pgid pgid //元数据页的id txid txid //最大的事务id checksum uint64//用作校验的校验和 }
type freelist struct { // 已经可以被分配的空闲页 ids []pgid // all free and available free page ids. // 将来很快能被释放的空闲页,部分事务可能在读或者写 pending map[txid][]pgid // mapping of soon-to-be free page ids by tx. cache map[pgid]bool// fast lookup of all free and pending page ids. }
freelist->page
将空闲列表转换成页信息,写到磁盘中,此处需要注意一个问题.
1 2 3 4
// write writes the page ids onto a freelist page. All free and pending ids are // saved to disk since in the event of a program crash, all pending ids will // become free. func(f *freelist) write(p *page) error {}
// Stop here if there are no items to write. if p.count == 0 { return }
// Loop over each item and write it to the page. // off tracks the offset into p of the start of the next data. // off: page 和 page elements 的头信息 off := unsafe.Sizeof(*p) + n.pageElementSize()*uintptr(len(n.inodes)) for i, item := range n.inodes { _assert(len(item.key) > 0, "write: zero-length inode key")
// Create a slice to write into of needed size and advance // byte pointer for next iteration. sz := len(item.key) + len(item.value) b := unsafeByteSlice(unsafe.Pointer(p), off, 0, sz) off += uintptr(sz)
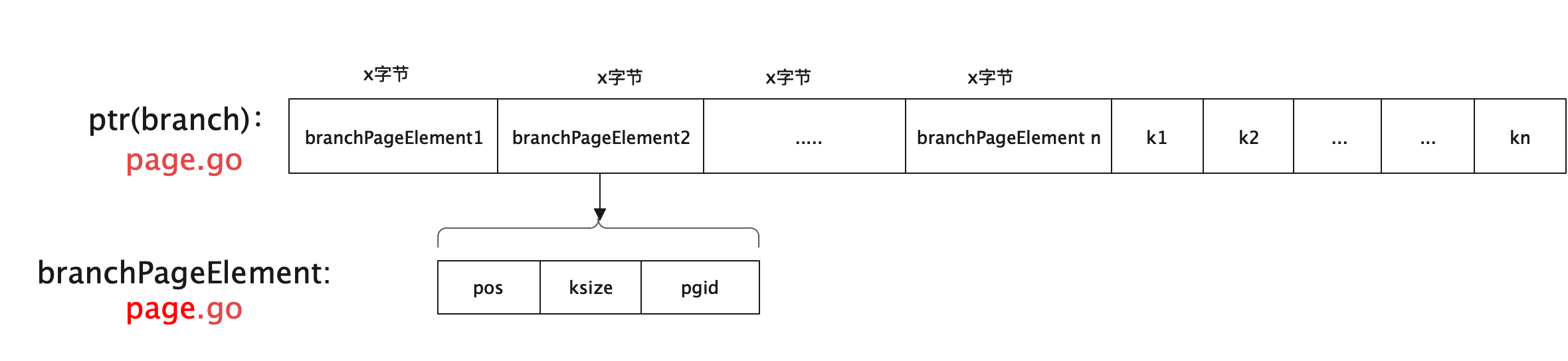
// Write the page element. // 1. 写一个节点的头信息 if n.isLeaf { elem := p.leafPageElement(uint16(i)) elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))) elem.flags = item.flags elem.ksize = uint32(len(item.key)) elem.vsize = uint32(len(item.value)) } else { elem := p.branchPageElement(uint16(i)) elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))) elem.ksize = uint32(len(item.key)) elem.pgid = item.pgid _assert(elem.pgid != p.id, "write: circular dependency occurred") } // 2. 写数据信息 // Write data for the element to the end of the page. l := copy(b, item.key) copy(b[l:], item.value) }
// leafPageElement represents a node on a leaf page. // 叶子节点既存储key,也存储value type leafPageElement struct { flags uint32//该值主要用来区分,是子桶叶子节点元素还是普通的key/value叶子节点元素。flags值为1时表示子桶。否则为key/value pos uint32 ksize uint32 vsize uint32 }
// key returns a byte slice of the node key. func(n *leafPageElement) key() []byte { i := int(n.pos) j := i + int(n.ksize) return unsafeByteSlice(unsafe.Pointer(n), 0, i, j) }
// value returns a byte slice of the node value. func(n *leafPageElement) value() []byte { i := int(n.pos) + int(n.ksize) j := i + int(n.vsize) return unsafeByteSlice(unsafe.Pointer(n), 0, i, j) }
// leafPageElement retrieves the leaf node by index func(p *page) leafPageElement(index uint16) *leafPageElement { return (*leafPageElement)(unsafeIndex(unsafe.Pointer(p), unsafe.Sizeof(*p), leafPageElementSize, int(index))) }
// leafPageElements retrieves a list of leaf nodes. func(p *page) leafPageElements() []leafPageElement { if p.count == 0 { returnnil } var elems []leafPageElement data := unsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p)) unsafeSlice(unsafe.Pointer(&elems), data, int(p.count)) return elems }