[TOC]
概述
Cache :即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提高了系统的效率。Cache又分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。(百度百科解释)。
多级缓存
随着科技发展,热点数据的体积越来越大,单纯的增加一级缓存大小的性价比已经很低了。因此,就慢慢出现了在一级缓存(L1 Cache)和内存之间又增加一层访问速度和成本都介于两者之间的二级缓存(L2 Cache)。此外,又由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache也被划分成L1i (i for instruction)和L1d (d for data)两种专门用途的缓存。
cache line
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个
数组访问实验:当数组小于64Bytes时数组极有可能落在一条Cache Line内,而一个元素的访问就会使得整条Cache Line被填充,因而值得后面的若干个元素受益于缓存带来的加速。而当数组大于64Bytes时,必然至少需要两条Cache Line,继而在循环访问时会出现两次Cache Line的填充,由于缓存填充的时间远高于数据访问的响应时间,因此多一次缓存填充对于总执行的影响会被放大
下面第一段代码在C语言中总是比第二段代码的执行速度要快。
1 | // 按行读取 |
1 | // 按列读取 |
按行读取为什么快
二维数组的内存地址是连续的,当前行的尾与下一行的头相邻
缓存从内存中抓取一般都是整个数据块,所以它的物理内存是连续的,几乎都是同行不同列的,而如果内循环以列的方式进行遍历的话,将会使整个缓存块无法被利用,而不得不从内存中读取数据,而从内存读取速度是远远小于从缓存中读取数据的。随着数组元素越来越多,按列读取速度也会越来越慢。
cache存放策略
省略
cache淘汰策略
在文章的最后我们顺带提一下CPU Cache的淘汰策略。常见的淘汰策略主要有LRU和Random两种。通常意义下LRU对于Cache的命中率会比Random更好,所以CPU Cache的淘汰策略选择的是LRU。当然也有些实验显示在Cache Size较大的时候Random策略会有更高的命中率
计算机存储体系
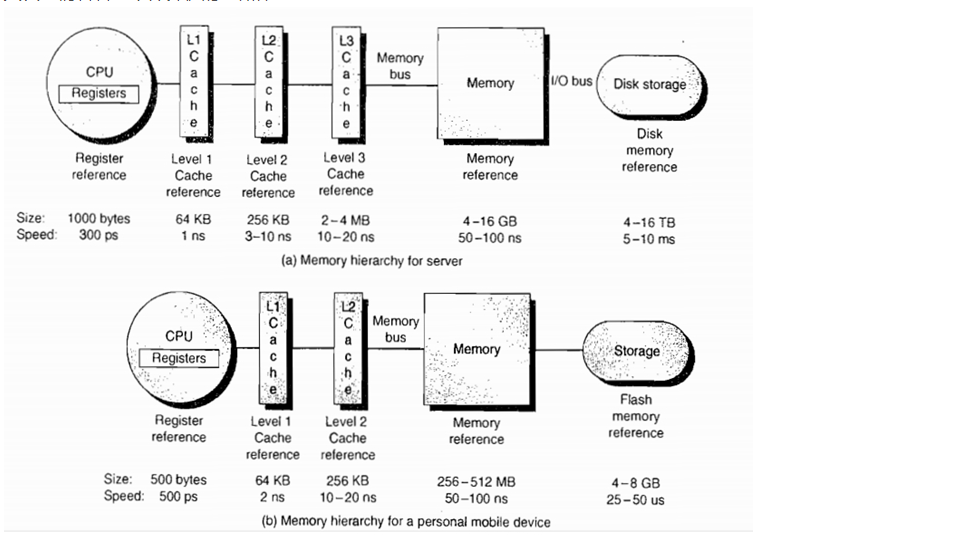
Register
寄存器是CPU的内部组成单元,是CPU运算时取指令和数据的地方,速度很快,寄存器可以用来暂存指令、数据和地址。在CPU中,通常有通用寄存器,如指令寄存器IR;特殊功能寄存器,如程序计数器PC、sp等。
Cache
缓存即就是用于暂时存放内存中的数据,若果寄存器要取内存中的一部分数据时,可直接从缓存中取到,这样可以调高速度。高速缓存是内存的部分拷贝。
Memory
内存的工作方式就要复杂得多:
- 找到数据的指针。(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
- 将指针送往内存管理单元(MMU),由MMU将虚拟的内存地址翻译成实际的物理地址。
- 将物理地址送往内存控制器(memory controller),由内存控制器找出该地址在哪一根内存插槽(bank)上。
- 确定数据在哪一个内存块(chunk)上,从该块读取数据。
- 数据先送回内存控制器,再送回CPU,然后开始使用。
内存的工作流程比寄存器多出许多步。每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。
disk
磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘(Hard disk,简称硬盘)。硬盘有机械硬盘(HDD)和固态硬盘(SSD)之分。
机械硬盘即是传统普通硬盘,主要由:盘片,磁头,盘片转轴及控制电机。
固态硬盘是用固态电子存储芯片阵列制成的硬盘。
主频
CPU主频
主频即CPU的时钟频率,计算机的操作在时钟信号的控制下分步执行,每个时钟信号周期完成一步操作,时钟频率的高低在很大程度上反映了CPU速度的快慢。主频不要理解成计算机执行指令的频率了,一个指令是在几个时钟周期完成和很多因素有关。
对于上面的内存取数据的执行过程中,每个操作都需要占用一个时钟周期,对于一个操作内存的加法,就需要5个时钟周期,换句话说,500Mhz主频的CPU,最多执行100MHz条指令。对于CPU来说读/写寄存器是不需要时间的,或者说如果只是操作寄存器(比如类似mov BX,AX之类的操作),那么一秒钟执行的指令个数理论上说就等于主频,因为寄存器是CPU的一部分。所以一个操作需要几条时钟周期也会影响执行速度。
内存访问速度
- 内存本身更慢:内存的主频现在主流是1333左右吧?或者1600,单位是MHz,这比CPU的速度要低的多,所以内存的速度起点就更低。
- 内存忙碌:内存不仅仅要跟CPU通信,还要通过DMA控制器与其它硬件通信,CPU要发起一次内存请求,先要给一个信号说“我要访问数据了,你忙不忙?”如果此时内存忙,则通信需要等待,不忙的时候,通信才能正常。并且,这个请求信号的时间代价,就是够执行几个汇编指令了,所以,这是内存慢的一个原因。
- 内存总线:内存跟CPU之间通信的通道也是有限的,就是所谓的“总线带宽”,但,要记住这个带宽不仅仅是留给内存的,还包括显存之类的各种通信都要走这条路,并且由于路是共享的,所以任何请求发起之间都要先抢占,抢占带宽需要时间,带宽不够等待的话也需要时间。