[TOC]
概述
- G — 表示 Goroutine,它是一个待执行的任务;
- M — 表示操作系统的线程,它由操作系统的调度器调度和管理;
- P — 表示处理器,它可以被看做运行在线程上的本地调度器,处理器;
抢占式调度
G-M-P 模型 (1.1)
工作原理
- 在当前的 G-M 模型中引入了处理器 P,增加中间层;
- 在处理器 P 的基础上实现基于工作窃取的调度器;
基于工作窃取的多线程调度器将每一个线程绑定到了独立的 CPU 上,这些线程会被不同处理器管理,不同的处理器通过工作窃取对任务进行再分配实现任务的平衡,也能提升调度器和 Go 语言程序的整体性能,今天所有的 Go 语言服务都受益于这一改动。
关键:工作窃取
解决的问题
解决锁竞争带来的性能问题
- 调度器和锁是全局资源,所有的调度状态都是中心化存储的,锁竞争问严重;
- 线程需要经常互相传递可运行的 Goroutine,引入了大量的延迟;
- 每个线程都需要处理内存缓存,导致大量的内存占用并影响数据局部性;
- 系统调用频繁阻塞和解除阻塞正在运行的线程,增加了额外开销;
缺点
但是 1.1 版本中的调度器仍然不支持抢占式调度,程序只能依靠 Goroutine 主动让出 CPU 资源才能触发调度。
基于协作的抢占式调度(1.2~1.13)
Go 语言会在分段栈的机制上实现抢占调度,利用编译器在分段栈上插入的函数,所有 Goroutine 在函数调用时都有机会进入运行时检查是否需要执行抢占。
工作原理
- 编译器会在调用函数前插入 runtime.morestack;
- Go 语言运行时会在垃圾回收暂停程序、系统监控发现 Goroutine 运行超过 10ms 时发出抢占请求 StackPreempt;
- 当发生函数调用时,可能会执行编译器插入的 runtime.morestack,它调用的 runtime.newstack 会检查 Goroutine 的 stackguard0 字段是否为 StackPreempt;
- 如果 stackguard0 是 StackPreempt,就会触发抢占让出当前线程;
这种实现方式虽然增加了运行时的复杂度,但是实现相对简单,也没有带来过多的额外开销,总体来看还是比较成功的实现,也在 Go 语言中使用了 10 几个版本。因为这里的抢占是通过编译器插入函数实现的,还是需要函数调用作为入口才能触发抢占,所以这是一种协作式的抢占式调度。
解决的问题
- 某些 Goroutine 可以长时间占用线程,造成其它 Goroutine 的饥饿;
- 垃圾回收需要暂停整个程序(Stop-the-world,STW),最长可能需要几分钟的时间,导致整个程序无法工作;
缺点
不够好
基于信号的抢占式调度
STW 和栈扫描是一个可以抢占的安全点(Safe-points),所以 Go 语言会在这里先加入抢占功能。基于信号的抢占式调度只解决了垃圾回收和栈扫描时存在的问题,它到目前为止没有解决所有问题,但是这种真抢占式调度是调度器走向完备的开始,相信在未来我们会在更多的地方触发抢占。
G
Goroutine 是 Go 语言调度器中待执行的任务,它在运行时调度器中的地位与线程在操作系统中差不多,但是它占用了更小的内存空间,也降低了上下文切换的开销。
Goroutine 只存在于 Go 语言的运行时,它是 Go 语言在用户态提供的线程,作为一种粒度更细的资源调度单元,如果使用得当能够在高并发的场景下更高效地利用机器的 CPU。
Goroutine 在 Go 语言运行时使用私有结构体 runtime.g 表示。
Goroutine 的状态
结构体 runtime.g 的 atomicstatus 字段存储了当前 Goroutine 的状态。除了几个已经不被使用的以及与 GC 相关的状态之外,Goroutine 可能处于以下 9 种状态:
| 状态 | 描述 |
|---|---|
_Gidle |
刚刚被分配并且还没有被初始化 |
_Grunnable |
没有执行代码,没有栈的所有权,存储在运行队列中 |
_Grunning |
可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
_Gsyscall |
正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
_Gwaiting |
由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
_Gdead |
没有被使用,没有执行代码,可能有分配的栈 |
_Gcopystack |
栈正在被拷贝,没有执行代码,不在运行队列上 |
_Gpreempted |
由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
_Gscan |
GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
虽然 Goroutine 在运行时中定义的状态非常多而且复杂,但是我们可以将这些不同的状态聚合成三种:等待中、可运行、运行中,运行期间会在这三种状态来回切换:
- 等待中:Goroutine 正在等待某些条件满足,例如:系统调用结束等,包括
_Gwaiting、_Gsyscall和_Gpreempted几个状态; - 可运行:Goroutine 已经准备就绪,可以在线程运行,如果当前程序中有非常多的 Goroutine,每个 Goroutine 就可能会等待更多的时间,即
_Grunnable; - 运行中:Goroutine 正在某个线程上运行,即
_Grunning;

M
CPU 和活跃线程
Go 语言并发模型中的 M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。
在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS 来改变最大的活跃线程数。
Go 语言会使用私有结构体 runtime.m 表示操作系统线程,这个结构体也包含了几十个字段.
调度 Goroutine 和运行 Goroutine
1 | type m struct { |
其中 g0 是持有调度栈的 Goroutine,curg 是在当前线程上运行的用户 Goroutine,这也是操作系统线程唯一关心的两个 Goroutine。
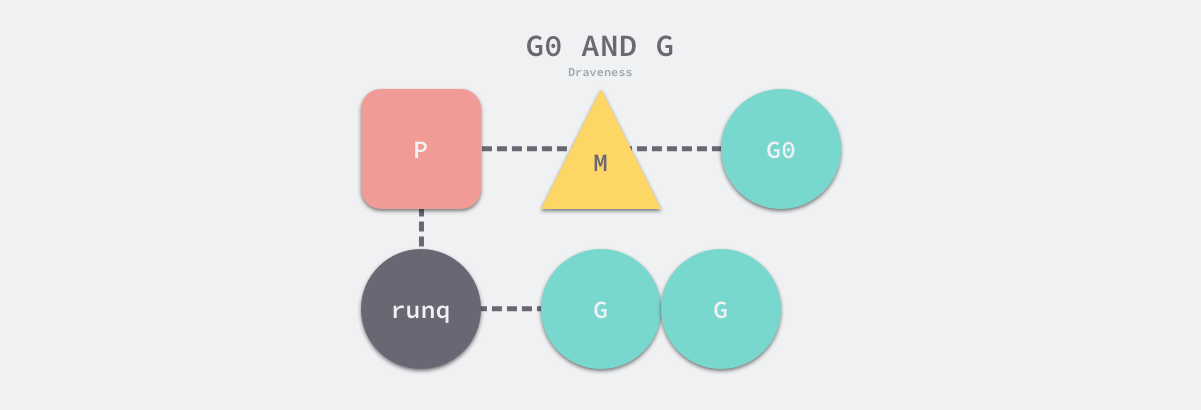
g0 是一个运行时中比较特殊的 Goroutine,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行。
runtime.m 结构体中还存在三个与处理器相关的字段,它们分别表示正在运行代码的处理器 p、暂存的处理器 nextp 和执行系统调用之前使用线程的处理器 oldp:
1 | type m struct { |
P
调度器中的处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
runtime.p 是处理器的运行时表示,作为调度器的内部实现,它包含的字段也非常多,其中包括与性能追踪、垃圾回收和计时器相关的字段,这些字段也非常重要,但是在这里就不展示了,我们主要关注处理器中的线程和运行队列:
1 | type p struct { |
反向存储的线程维护着线程与处理器之间的关系,而 runhead、runqtail 和 runq 三个字段表示处理器持有的运行队列,其中存储着待执行的 Goroutine 列表,runnext 中是线程下一个需要执行的 Goroutine。
| 状态 | 描述 |
|---|---|
_Pidle |
处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
_Prunning |
被线程 M 持有,并且正在执行用户代码或者调度器 |
_Psyscall |
没有执行用户代码,当前线程陷入系统调用 |
_Pgcstop |
被线程 M 持有,当前处理器由于垃圾回收被停止 |
_Pdead |
当前处理器已经不被使用 |
通过分析处理器 P 的状态,我们能够对处理器的工作过程有一些简单理解,例如处理器在执行用户代码时会处于 _Prunning 状态,在当前线程执行 I/O 操作时会陷入 _Psyscall 状态。
调度器启动
调度器的启动过程是我们平时比较难以接触的过程,不过作为程序启动前的准备工作,理解调度器的启动过程对我们理解调度器的实现原理很有帮助,运行时通过 runtime.schedinit 初始化调度器:
调用 runtime.procresize 是调度器启动的最后一步,在这一步过后调度器会完成相应数量处理器的启动,等待用户创建运行新的 Goroutine 并为 Goroutine 调度处理器资源。
创建 Goroutine
想要启动一个新的 Goroutine 来执行任务时,我们需要使用 Go 语言的 go 关键字,编译器会通过 cmd/compile/internal/gc.state.stmt 和 cmd/compile/internal/gc.state.call 两个方法将该关键字转换成 runtime.newproc 函数调用:
newproc
runtime.newproc 的入参是参数大小和表示函数的指针 funcval,它会获取 Goroutine 以及调用方的程序计数器,然后调用 runtime.newproc1 函数获取新的 Goroutine 结构体、将其加入处理器的运行队列并在满足条件时调用 runtime.wakep 唤醒新的处理执行 Goroutine:
1 | func newproc(siz int32, fn *funcval) { |
初始化 g 结构体(newproc1)
runtime.gfget 通过两种不同的方式获取新的 runtime.g:
- 从 Goroutine 所在处理器的 gFree 列表或者调度器的 sched.gFree 列表中获取 runtime.g;
- 调用 runtime.malg 生成一个新的 runtime.g 并将结构体追加到全局的 Goroutine 列表 allgs 中。
runtime.gfget
runtime.gfget 中包含两部分逻辑,它会根据处理器中 gFree 列表中 Goroutine 的数量做出不同的决策:
- 当处理器的 Goroutine 列表为空时,会将调度器持有的空闲 Goroutine 转移到当前处理器上,直到 gFree 列表中的 Goroutine 数量达到 32;
- 当处理器的 Goroutine 数量充足时,会从列表头部返回一个新的 Goroutine;
malg
当调度器的 gFree 和处理器的 gFree 列表都不存在结构体时,运行时会调用 runtime.malg 初始化新的 runtime.g 结构,如果申请的堆栈大小大于 0,这里会通过 runtime.stackalloc 分配 2KB 的栈空间
allgadd
1 | allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. |
运行队列 (runqput)
runtime.runqput 会将 Goroutine 放到运行队列上,这既可能是全局的运行队列,也可能是处理器本地的运行队列:
- 当 next 为 true 时,将 Goroutine 设置到处理器的 runnext 作为下一个处理器执行的任务;
- 当 next 为 false 并且本地运行队列还有剩余空间时,将 Goroutine 加入处理器持有的本地运行队列;
- 当处理器的本地运行队列已经没有剩余空间时就会把本地队列中的一部分 Goroutine 和待加入的 Goroutine 通过 runtime.runqputslow 添加到调度器持有的全局运行队列上;
1 | retry: |
处理器本地的运行队列是一个使用数组构成的环形链表,它最多可以存储 256 个待执行任务。
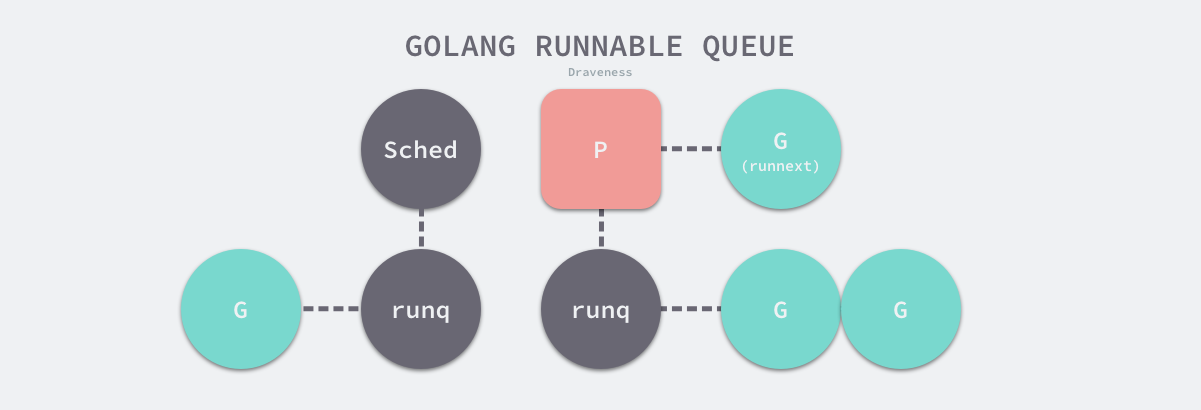
简单总结一下,Go 语言有两个运行队列,其中一个是处理器本地的运行队列,另一个是调度器持有的全局运行队列,只有在本地运行队列没有剩余空间时才会使用全局队列。
调度信息
运行时创建 Goroutine 时会通过下面的代码设置调度相关的信息,前两行代码会分别将程序计数器和 Goroutine 设置成 runtime.goexit 和新创建 Goroutine 运行的函数:
1 | newg.sched.pc = funcPC(goexit) + sys.PCQuantum |
调度信息的 sp 中存储了 runtime.goexit 函数的程序计数器,而 pc 中存储了传入函数的程序计数器。因为 pc 寄存器的作用就是存储程序接下来运行的位置,所以 pc 的使用比较好理解,但是 sp 中存储的 runtime.goexit 会让人感到困惑,我们需要配合下面的调度循环来理解它的作用。
调度循环
调度器启动之后,Go 语言运行时会调用 runtime.mstart 以及 runtime.mstart1,前者会初始化 g0 的 stackguard0 和 stackguard1 字段,后者会初始化线程并调用 runtime.schedule 进入调度循环:
1 | if gp == nil { |
runtime.schedule (调度入口)
runtime.schedule 函数会从下面几个地方查找待执行的 Goroutine:
- 为了保证公平,当全局运行队列中有待执行的 Goroutine 时,通过 schedtick 保证有一定几率会从全局的运行队列中查找对应的 Goroutine;
- 从处理器本地的运行队列中查找待执行的 Goroutine;
- 如果前两种方法都没有找到 Goroutine,会通过 runtime.findrunnable 进行阻塞地查找 Goroutine;
runtime.findrunnable (兜底找 g)
runtime.findrunnable 的实现非常复杂,这个 300 多行的函数通过以下的过程获取可运行的 Goroutine:
从本地运行队列、全局运行队列中查找;
从网络轮询器中查找是否有 Goroutine 等待运行;
通过 runtime.runqsteal 尝试从其他随机的处理器中窃取待运行的 Goroutine,该函数还可能窃取处理器的计时器;
因为函数的实现过于复杂,上述的执行过程是经过简化的,总而言之,当前函数一定会返回一个可执行的 Goroutine,如果当前不存在就会阻塞等待。
1 | func findrunnable() (gp *g, inheritTime bool) { |
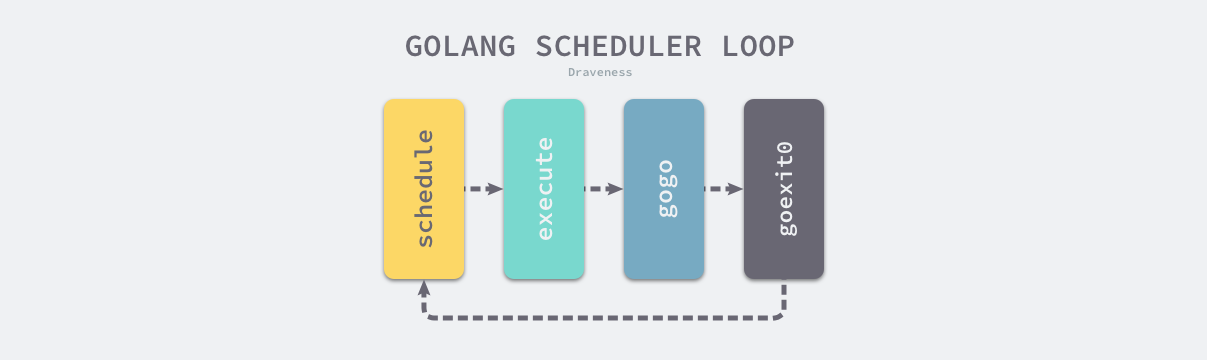
runtime.execute (执行 g)
接下来由 runtime.execute 执行获取的 Goroutine,做好准备工作后,它会通过 runtime.gogo 将 Goroutine 调度到当前线程上。
1 | func execute(gp *g, inheritTime bool) { |
gogo
在函数调用一节中,我们曾经介绍过 Go 语言的调用惯例,正常的函数调用都会使用 CALL 指令,该指令会将调用方的返回地址加入栈寄存器 SP 中,然后跳转到目标函数;当目标函数返回后,会从栈中查找调用的地址并跳转回调用方继续执行剩下的代码。
runtime.gogo 就利用了 Go 语言的调用惯例成功模拟这一调用过程,通过以下几个关键指令模拟 CALL 的过程:
1 | MOVL gobuf_sp(BX), SP // 将 runtime.goexit 函数的 PC 恢复到 SP 中 |
goexit0 -> schedule
1 | func goexit0(gp *g) { |
在最后 runtime.goexit0 会重新调用 runtime.schedule 触发新一轮的 Goroutine 调度,Go 语言中的运行时调度循环会从 runtime.schedule 开始,最终又回到 runtime.schedule,我们可以认为调度循环永远都不会返回。
触发调度
这里简单介绍下所有触发调度的时间点,因为调度器的 runtime.schedule 会重新选择 Goroutine 在线程上执行,所以我们只要找到该函数的调用方就能找到所有触发调度的时间点,经过分析和整理,我们能得到如下的树形结构:
调度时间点
除了上图中可能触发调度的时间点,运行时还会在线程启动 runtime.mstart 和 Goroutine 执行结束 runtime.goexit0 触发调度。我们在这里会重点介绍运行时触发调度的几个路径:
- 主动挂起 —
runtime.gopark->runtime.park_m - 系统调用 —
runtime.exitsyscall->runtime.exitsyscall0 - 协作式调度 —
runtime.Gosched->runtime.gosched_m->runtime.goschedImpl - 系统监控 —
runtime.sysmon->runtime.retake->runtime.preemptone
主动挂起
gopark
runtime.gopark 是触发调度最常见的方法,该函数会将当前 Goroutine 暂停,被暂停的任务不会放回运行队列,我们来分析该函数的实现原理:
runtime.gopark 会通过 runtime.mcall 切换到 g0 的栈上调用 runtime.park_m.
runtime.park_m 会将当前 Goroutine 的状态从 _Grunning 切换至 _Gwaiting,调用 runtime.dropg 移除线程和 Goroutine 之间的关联(此时 M 上没有 g,触发调度后为 M 找一个 g),在这之后就可以调用 runtime.schedule 触发新一轮的调度了。
ready
当 Goroutine 等待的特定条件满足后,运行时会调用 runtime.goready 将因为调用 runtime.gopark 而陷入休眠的 Goroutine 唤醒。
runtime.ready 会将准备就绪的 Goroutine 的状态切换至 _Grunnable 并将其加入处理器的运行队列中,等待调度器的调度。
系统调用
省略
协作式调度
我们在设计原理中介绍过了 Go 语言基于协作式和信号的两种抢占式调度,这里主要介绍其中的协作式调度。runtime.Gosched 函数会主动让出处理器,允许其他 Goroutine 运行。该函数无法挂起 Goroutine,调度器会在可能会将当前 Goroutine 调度到其他线程上:
1 | // Gosched yields the processor, allowing other goroutines to run. It does not |
Q&A
为什么一定要有上下文?(P, 准确来说,是处理器哈)
- 阻塞的情况:如果G被阻塞在某个system call操作上,那么不光G会阻塞,执行该G的M也会解绑P(实质是被sysmon抢走了),与G一起进入sleep状态。如果此时有idle的M,则P与其绑定继续执行其他G;如果没有idle M,但仍然有其他G要去执行,那么就会创建一个新M。(注意,Go 语言并发模型中的 M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有
GOMAXPROCS个活跃线程能够正常运行。) - 解决了很多 GM 模型的缺点,如锁竞争, 线程传递g开销大,线程内存缓存太多(影响数据局部性)
总体来说,M 应该和一个稳定的用户态数据绑定。
参考
这个比较厉害:https://tonybai.com/2017/06/23/an-intro-about-goroutine-scheduler/