[TOC]
开篇
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流
- 缓存:缓存的目的是提升系统访问速度和增大系统处理容量
- 降级:降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行
- 限流:限流的目的是通过对并发访问/请求进行限速,或者对一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理
漏斗桶概览
文献中描述了两种不同的应用漏斗类比的方法。[1] [2] [3] [4]这些给出了似乎是两种不同的算法,这两种算法都称为漏斗算法,通常不参考其他方法。这导致了关于漏桶算法是什么及其性质的困惑。
在其中一种类比的实现中,存储桶的类比是计数器或变量,与流量或事件调度分开。[1] [3] [4]此计数器仅用于检查流量或事件是否符合限制:当每个数据包到达进行检查或发生事件的点时,该计数器就会递增,这等效于间歇地向其中添加水的方式桶。计数器也以固定的速率递减,这与水从水桶漏出的方式相同。结果,计数器中的值代表类似桶中的水位。如果在数据包到达时或事件发生时计数器保持在指定的限值以下,即存储桶未溢出,则表明其符合带宽和突发性限值或平均和峰值速率事件限值。因此,在此版本中,水的类似物由数据包或事件携带,在到达或发生时添加到水桶中,然后泄漏出去。此版本在这里称为漏斗式计量表。
在第二个版本中,桶的类似物是交通流中的一个队列。[2]此队列用于直接控制流量:数据包到达时将其输入到队列中,相当于将水添加到桶中。然后通常以固定的速率,例如从队列中将这些分组从队列中删除(先到先服务)。向前传输,相当于水从桶中漏出。结果,为队列提供服务的速率直接控制流量的向前传输速率。因此,它强加一致性而不是检查一致性,并且在以固定速率为队列提供服务的情况下(以及数据包的长度均相同),所得到的流量必然没有突发性或抖动。因此,在此版本中,流量本身就是流过水桶的水的类似物。目前尚不清楚这种应用类比的版本如何用于检查离散事件的发生率。此版本在此处称为泄漏存储桶作为队列。
作为仪表的泄漏桶与令牌桶算法完全相同(即镜像),即,向泄漏桶加水的过程恰好反映了在合格数据包到达时从令牌桶中删除令牌的过程,即从漏水桶漏水完全反映了定期向令牌桶中添加令牌的过程,漏水桶不会溢出的测试也反映了令牌桶包含足够的令牌并且不会“下溢”的测试。因此,在给定等效参数的情况下,这两种算法将看到相同的流量,即符合或不符合。可以将漏斗作为队列视为漏斗作为仪表的特例。[6]
AS A METER
乔纳森·S·特纳(Jonathan S. Turner)对漏斗算法的原始描述有功劳[7],其描述如下:“与每个在连接上传输的用户相关的计数器,每当用户发送一个数据包时就增加,并周期性地减少。 计数器增加后超过阈值,网络将丢弃该数据包。用户指定计数器减少的速率(这确定平均带宽)和阈值(突发性的度量)”。[1] 在这种情况下,存储桶(类似于计数器)被用作计量器来测试数据包的一致性,而不是用作直接控制数据包的队列。
ITU-T在建议I.371和ATM论坛的UNI规范中给出了对该算法的本质上相同的仪表版本(通用信元速率算法)的另一种描述。[3] [4] ITU-T给出了以下描述,其中术语“单元”等效于特纳描述[1]中的数据包:“连续状态泄漏桶可以看作是一个容量有限的桶,其实际值内容会以每个时间单位1个单位的内容的连续速率耗尽,并且每个合格单元格的内容以增量T递增…如果在单元格到达时,存储桶的内容小于或等于极限值τ,则[4]该单元格是合格的;否则,该单元格是不合格的。存储桶的容量(计数器的上限)为(T +τ)“。[4]这些规范还指出,由于其有限的容量,如果在测试一致性时漏斗的内容物大于极限值,并且因此单元格不合格,则漏斗保持不变;否则,漏斗将保持不变。也就是说,如果会使水桶溢出,则根本不添加水。
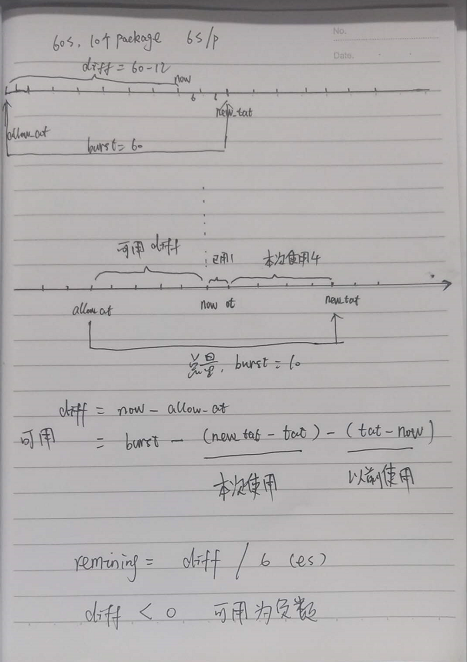
可以将泄漏存储桶算法作为一种可以在流量监管或流量整形中使用的仪表的操作概念描述如下:
1 | emission_interval = period / rate # 60 / 100 # 一个包需要 0.6 秒才能处理完 0.6s/package |
- 与每个虚拟连接或用户关联的固定容量的存储桶以固定的速率泄漏。
- 速率 = 时长 / 数据包个数, 例如,在一分钟内,只能处理, 100 个 数据包,那么速率是 60 / 100
- 如果漏斗是空的,它将停止泄漏。
- 为了使包装符合要求,必须向桶中添加一定量的水:符合要求的包所添加的特定量对于所有包都可以相同,或者与包的长度成比例。
- 如果此水量会使水桶超出其容量,则说明包不合格,水桶中的水保持不变。
图解如下
lua script
1 | -- Copyright (c) 2017 Pavel Pravosud |
AS A QUEUE
uber-go 实现的漏斗桶算法 (as a queue), 比较简单的非分布式漏斗桶,代码如下
主要是基于 sleep 函数做速率控制。所以核心实际上是计算 需要睡眠的时间, 需要睡眠的时间由两部分组成,一部分是每一个请求需要花费的时间 perRequest, 另一个是之前的所有请求所使用了的时间 now.Sub(oldState.last), 如果这个时间为正数, 说明前面一段时间处理不是很忙碌,现在能处理更多的请求。如果这个时间为负数,说明前面已经排队了很多请求,这里需要更多的睡眠时间。
- 如果是第一次调用 Take 函数,那么直接返回,并设置 state.last = now
- 如果是非第一次调用 Take 函数,那么计算当前请求需要休眠的时间
newState.sleepFor += t.perRequest - now.Sub(oldState.last)- 其中 perRequest 表示每一个请求需要的理论平均时间,例如该 limiter 初始化为 100 qps,那么 preRequest 就是 0.01 s, 对应的初始化代码
perRequest: time.Second / time.Duration(rate)
- 其中 perRequest 表示每一个请求需要的理论平均时间,例如该 limiter 初始化为 100 qps,那么 preRequest 就是 0.01 s, 对应的初始化代码
- 然后更新 state.last
newState.last = now; newState.last = newState.last.Add(newState.sleepFor) - 然后 sleep
1 | func (t *limiter) Take() time.Time { |
参考:
go redis 实现分布式漏斗桶算法 (as a meter)
下一篇谷歌实现的令牌桶算法,有时间再看了,https://github.com/golang/time