[TOC]
以下无特殊说明,都是 mysql InnoDB 引擎下讨论。
我们清楚InnoDB中主键索引B+树是如何组织数据、查询数据的,我们总结一下:
- InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值(id)+指针,在B+树中叶子节点存放数据,非叶子节点存放键值+指针。
- 索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据;
B+树数据页面结构
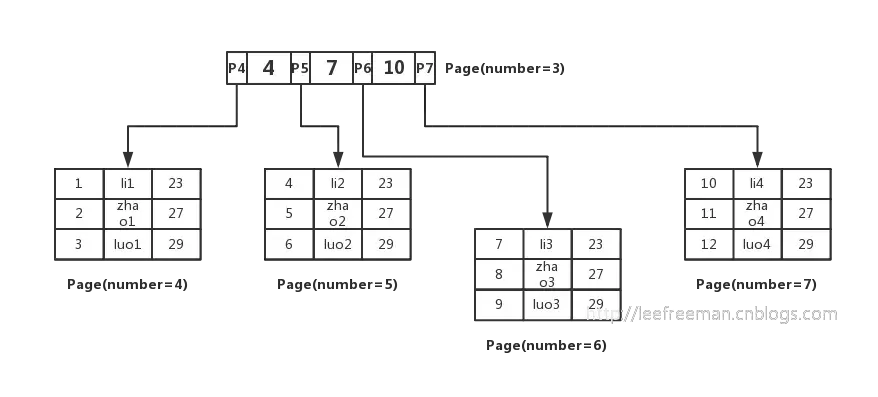
索引组织表
InnoDB是索引组织表, 所以 InnoDB 必须有主键索引。大多数情况下主键索引都是一列自增的 ID。详细规则如下:
- 如果一个主键被定义了,那么这个主键就是作为聚集索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
- 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
索引组织表也就意味着,主键索引文件就是数据文件,因为主键索引文件的叶节点包含完整的数据记录。
分类
从数据结构角度
- B+树索引(O(log(n)))
- hash索引
- 仅仅能满足”=”,”IN”和”<=>”查询,不能使用范围查询
- 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到叶节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
- 只有Memory存储引擎显示支持hash索引
- FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了)
- InnoDB 自适应哈希索引(不是一种索引)
- 自适应哈希仅由数据库创建并使用,对范围查询无效,只对字典类型(等值查询)的查询有效。
从物理存储角度
- 聚集索引(clustered index)
- 非聚集索引(non-clustered index)
从逻辑角度
- 主键索引:主键索引是一种特殊的唯一索引,不允许有空值
- 普通索引或者单列索引
- 多列索引(复合索引, 联合索引):复合索引指多个字段上创建的索引。使用复合索引时遵循最左前缀集合
- 唯一索引或者非唯一索引
从使用效果来说
- 覆盖索引(非聚集索引)
- 覆盖索引:一个查询的结果从索引中就能全部获得,也称为索引覆盖(**(索引 + id**) 覆盖了查询结果)。
- 主键索引查询只会查一次,而非主键索引需要回表查询多次(回表)。但是如果使用覆盖索引,那么还是只会查一次。
复合索引
为什么使用复合索引
参考另一篇文章
多个字段的顺序,一般是根据业务需求,将区分度高的放在左边。
索引数据结构
B+Tree 的优劣势
InnoDB 的主键索引使用的是 B+Tree,节点存储着主键索引的值(方便做等值查询),叶子节点存储着完整的数据,且使用链表(双向链表)连接(方便范围查询)。
- 适合范围查询,适合等值查询
- 可以使用索引完成排序
- 支持复合索引的最左匹配原则
- 大量重复的键值只会导致索引的区分度小,如果业务需要可以强制走索引
select * from mytable force index(day_index) where day = 20200101 limit 2,强制走day_index索引
hash 的优劣势
- 哈希索引适合等值查询,无法进行范围查询
- 哈希索引无法利用索引完成排序
- 哈希索引的多列索引不支持最左匹配原则
- 大量重复的键值会导致大量的哈希碰撞
B-Tree 的优劣势
- 适合等值查询, 不适合范围查询
- 不可以使用索引完成排序
- 支持复合索引的最左匹配原则
- 因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(而B+树的非叶子结点只需要存储主键和指针就可以了)(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
- 大量重复的键值只会导致索引的区分度小,如果业务需要可以强制走索引
db.users.find({"age":1,"username": "percy"}).hint({"username":1,"age":1})
为什么 MongoDB 使用 B-Tree
MongoDB 作为面向文档的数据库,与数据之间的关系相比,它更看重以文档为中心的组织方式(因为 B 树的所有节点都能存储数据),所以选择了查询单个文档性能较好的 B 树,这个选择对遍历数据的查询也可以保证可以接受的时延;
索引失效
查询优化器
一条 SQL 语句的查询,可以有不同的执行方案,至于最终选择哪种方案,是查询优化器选择的。流程如下:
- 根据搜索条件,找出所有可以使用的索引
- 计算全表扫描的代价
- 计算不同索引的查询代价
- 对比各种执行方案的代价,找出成本最低的那个
索引分析 explain
可以通过explain查看sql语句的执行计划,通过执行计划来分析索引使用情况
1 | | mytable | CREATE TABLE `mytable` ( |
结果如下,
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | mytable | NULL | range | name_day_key,day_name_key | name_day_key | 773 | NULL | 1 | 100.00 | Using index condition |
| 2 | SIMPLE | mytable | NULL | range | day_name_key | day_name_key | 5 | NULL | 1 | 100.00 | Using index condition |
Using index condition 表示使用了索引下推
type
常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 触发联合索引最左原则(不知道的搜下),或者这个索引不是主键,也不是唯一索引(换句话说,如果这个在这个索引基础之上查询的结果多于一行)。
const: 仅仅能查出一条的SQL语句并且用于Primary key 或 unique索引;
实践
面的笔记是根据我自己的 mysql 服务的版本号来的
1 | mysql> select version(); |
随便放一个查询结果,我们要说的就是这里的type的值。
1 | mysql> explain SELECT id,title FROM seo_php_article where is_delete=0 order by id asc limit 66500,500; |
The type column of EXPLAIN output describes how tables are joined. The following list describes the join types, ordered from the best type to the worst:
下面的从好到坏依次解释:
ref
All rows with matching index values are read from this table for each combination of rows from the previous tables. ref is used if the join uses only a leftmost prefix of the key or if the key is not a PRIMARY KEY or UNIQUE index (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.
第一句没理解透,先理解到多行匹配吧。
触发条件:触发联合索引最左原则(不知道的搜下),或者这个索引不是主键,也不是唯一索引(换句话说,如果这个在这个索引基础之上查询的结果多于一行)。
如果使用那个索引只匹配到非常少的行,也是不错的。
ref can be used for indexed columns that are compared using the = or <=> operator. In the following examples, MySQL can use a ref join to process ref_table:
在对已经建立索引列进行=或者<=>操作的时候,ref会被使用到。与eq_ref不同的是匹配到了多行
1 | # 根据索引(非主键,非唯一索引),匹配到多行 |
range
Only rows that are in a given range are retrieved, using an index to select the rows. The key column in the output row indicates which index is used. The key_len contains the longest key part that was used. The ref column is NULL for this type.
只有给定范围内的行才能被检索,使用索引来查询出多行。 输出行中的类决定了会使用哪个索引。 key_len列表示使用的最长的 key 部分。 这个类型的ref列是NULL。
range: 表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中.当 type 是 range 时, 那么 EXPLAIN 输出的 ref 字段为 NULL, 并且 key_len 字段是此次查询中使用到的索引的最长的那个.
range can be used when a key column is compared to a constant using any of the =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, or IN() operators:
1 | # 常量比较,可能多行(但是这里的例子和上面 ref 的第一个例子不一样吗?) |
index
The index join type is the same as ALL, except that the index tree is scanned. This occurs two ways:
- If the index is a covering index for the queries and can be used to satisfy all data required from the table, only the index tree is scanned. In this case, the Extra column says Using index. An index-only scan usually is faster than ALL because the size of the index usually is smaller than the table data.
- A full table scan is performed using reads from the index to look up data rows in index order. Uses index does not appear in the Extra column.
index类型和ALL类型一样,区别就是index类型是扫描的索引树。以下两种情况会触发:
- 如果索引是查询的覆盖索引,就是说索引查询的数据可以满足查询中所需的所有数据,则只扫描索引树,不需要回表查询。 在这种情况下,explain 的
Extra列的结果是Using index。仅索引扫描通常比ALL快,因为索引的大小通常小于表数据。 - 全表扫描会按索引的顺序来查找数据行。使用索引不会出现在
Extra列中。
例如查询索引列的全部数据
ALL
A full table scan is done for each combination of rows from the previous tables. This is normally not good if the table is the first table not marked const, and usually very bad in all other cases. Normally, you can avoid ALL by adding indexes that enable row retrieval from the table based on constant values or column values from earlier tables.
全表扫描就不用看了,赶快优化吧。
索引失效分析
偶现
必现
- like 的错误使用
- like语句要使索引生效,like后不能以%开始,也就是说 (like %字段名%) 、(like %字段名)这类语句会使索引失效,而(like 字段名)、(like 字段名%)这类语句索引是可以正常使用。
MYSQL5.6的索引小优化
MRR(multi range read)
1 | # 查看是否开启 |
Index Condition Pushdown 索引下推
从mysql 5.6 开始支持,之前的 mysql 数据库版本不支持索引下推。不支持时,在根据索引查询时,首先根据索引查找记录,然后根据 where 语句过滤记录。在支持索引下推后,mysql 数据库会在取出索引的同时,判断是否可以进行 where 条件过滤。
可以简单理解有两层, sql server 和 存储引擎层
第一个查询可以使用索引下推, 如下面举例,那么使用 day 索引查询,使用 name(由于使用这种like的写法导致索引失效) 做过滤。如果在5.6 以前,没有索引下推。那么引擎层就把 所以 查出来的数据全部返回给 sql server, sql server 再通过 name 来过滤。仔细想想,和覆盖索引的原理实际上有几分相似。Using index condition 表示使用了索引下推。
第二个查询不能使用索引下推,因为没有 day + num 的索引。
1 | # 查询是否开启 默认是开启的 |
执行结果
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | mytable | NULL | range | day_name_key | day_name_key | 5 | NULL | 900 | 11.11 | Using index condition |
| 1 | SIMPLE | mytable | NULL | range | day_name_key | day_name_key | 5 | NULL | 900 | 33.33 | Using index condition; Using where |
参考
《MySQL技术内幕(InnoDB存储引擎)第2版》