[TOC]
概述
分布式数据处理系统第一个要解决的问题就是如何将数据进行拆分,利用多台计算机处理大规模数据。对于数据量很大的数据集,单机无法保存或者处理时,通过对数据集进行水平拆分,将不同的数据子集存放到不同的处理节点,这种对数据进行拆分的方式叫做 分区(partition)。
不同数据库中对分区的名称定义有所差异,有些称之为分区(partition),有些称之为分片(sharding),还有一些称之为区域(Region),但是其含义都是基本相同的。需要注意的是,这里的分区跟 CAP 中的网络分区和单机的单机分区表没有关系。
分区partition在不同数据库有不同的称谓
Shard[分片]MongoDB,ElasticsearchRegion[区域]HBasetablet[表块]BigTablevnode[虚节点]Cassandra,Riak
对于大部分实现方案,数据被分区后,各个分区由不同的独立、完整的数据库进行保存和处理,然后由一个或多个协调节点进行请求的路由处理。
- CN: 协调节点(coordinator node),根据分区策略对数据做分区处理。
- DN: 数据节点(data node),用于保存数据,独立维护自己的元数据,通常都是完整的数据库,每个 DN 保存一个数据子集,每个数据子集都是一个分区。
分区需要考虑的问题
- 具体如何划分原始数据集?
- 当原问题的规模变大的时候,能否通过增加节点来动态适应?
- 当某个节点故障的时候,能否将该节点上的任务均衡的分摊到其他节点?
- 对于可修改的数据(比如数据库数据),如果某节点数据量变大,能否以及如何将部分数据迁移到其他负载较小的节点,及达到动态均衡的效果?
- 元数据的管理(即数据与物理节点的对应关系)规模?元数据更新的频率以及复杂度?
分区策略
对于一个分布式数据处理系统,将数据分布到多个分区有两种比较典型的方案:
- 一种是根据键做哈希,根据哈希值选择对应的数据节点。
- 另一种是范围分区,某一段连续的键都保存在一个数据节点上。
- 还有一种是一致性哈希, 将机器计算哈希值映射到一个[0, 2^32-1]的环上,数据键也做哈希映射
哈希分区 (partition hashing)
哈希分区是最常见的数据分区方式,通过按照数据的key、或者用户指定的一个或者多个字段计算哈希,然后将计算后的哈希与计算节点进行映射,从而将不同哈希值的数据分布到不同节点上。
例如,有3条记录(key1, value1), (key2, value2), (key3, value3) 通过对键进行计算哈希(对 key 进行 md5哈希,然后取前两个字符作为哈希值),哈希桶个数255个,当前有两个分区,偶数哈希值放到分区0,奇数哈希值放到分区1,计算后的数据分布如下图所示。
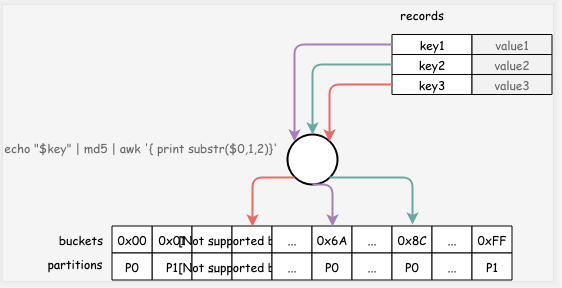
优缺点
哈希分区的一个优点是,保存的元数据很简单,只需要保存桶与分区的映射关系即可。但是缺点也很明显,可扩展性差,如果增加一个节点进行扩容,则需要对所有数据进行重新计算哈希,然后对数据进行重新分布,对于均匀分布的哈希函数而言,一般而言,在扩容时每个分区都需要扩容,通过成倍增加节点,然后通过调整映射关系,重新分布一半的数据到新分区。另一个缺点是,如果哈希函数选择不合理,则很容易出现数据倾斜,导致某个分区数据量很大。
范围分区 (partition range)
按数据范围分区是另一个常见的分布方式,通过按照数据的key、或者用户指定的一个或者多个字段计算所在的分区范围,从而确定数据所在的分区。
例如,一个简单的例子:key 小于等于 r 的分布到分区0,key 小于等于 z 的数据分布到分区1,三条记录(a, value1), (r, value2), (x, value3)则分别分布到了分区0,分区0,分区1中。
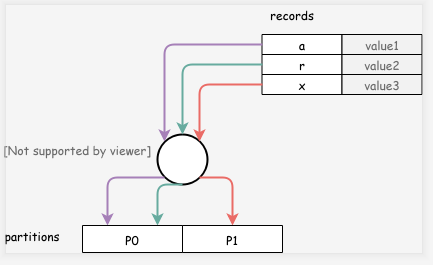
与哈希分布不一样的是,范围分区需要记录所有的数据分布情况,可能会有大量元数据。范围分区还有一个问题是,对于特定的数据处理请求可能会造成热点访问,例如我们按时间进行范围分区,每天的数据保存在一个分区上,则对某一天的数据查询处理,只能在这一个分区上进行,无法利用多分区的并行处理能力,这时就要求应用开发人员定义分片特征时,仔细选择特征字段进行范围分区。
一致性哈希分区(consistent hashing)
一致性哈希要解决的问题是集群的动态扩容问题。如哈希分区, 当集群增加节点时,最多可能所有的节点都需要迁移,这么大量的数据迁移是很难在工程上被接受的。所以有了一致性哈希算法。
一致性Hash的基本思想就是分两步走:
- 把object求hash(这一步和之前相同);
- 把cache也求hash,然后把object和cache的hash值放入一个环形hash空间,通过一定的规则决定每个object落在哪一个cache中。
一致性哈希算法的基本实现原理是将机器节点和key值都按照一样的hash算法映射到一个0~2^32的圆环上。当有一个写入缓存的请求到来时,计算Key值k对应的哈希值Hash(k),如果该值正好对应之前某个机器节点的Hash值,则直接写入该机器节点,如果没有对应的机器节点,则顺时针查找下一个节点,进行写入,如果超过2^32还没找到对应节点,则从0开始查找(因为是环状结构)。
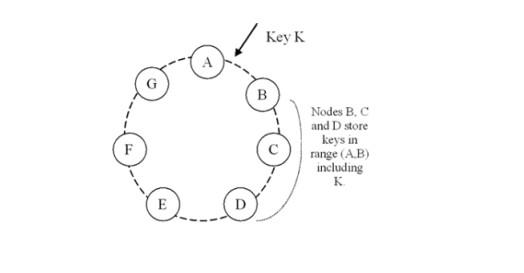
机器伸缩
经过一致性哈希算法散列之后,当有新的机器加入时,将只影响一台机器的存储情况,例如新加入的节点H的散列在B与C之间,则原先由C处理的一些数据可能将移至H处理,而其他所有节点的处理情况都将保持不变,因此表现出很好的单调性。而如果删除一台机器,例如删除C节点,此时原来由C处理的数据将移至D节点,而其它节点的处理情况仍然不变。而由于在机器节点散列和缓冲内容散列时都采用了同一种散列算法,因此也很好得降低了分散性和负载。而通过引入虚拟节点的方式,也大大提高了平衡性。
虚拟节点
另外具体机器映射时,还可以根据处理能力不同,将一个实体节点映射到多个虚拟节点, 实际上很像加权负载。
“虚拟节点”的hash计算可以采用对应节点的IP地址加数字后缀的方式。例如假设NODE1的IP地址为192.168.1.100。引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入“虚拟节点”后,计算“虚拟节”点NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1
Hash(“192.168.1.100#2”); // NODE1-2
Java 实现
https://github.com/ivalue2333/java-framework
其他策略
- 轮询:新增数据循环插入到不同的分区,每个分区数据均匀,但是对于数据请求路由,并不能根据请求的条件获取到所在的分区,查询或者更新时需要将请求发送给所有分区节点。
- 列表:指定数据分布方式,对于某个值指定所在的分区,例如,
(1, 2, 4) in P0,(3, 5) in P1。 - 动态分区:单独的定位器服务跟踪节点之间的分区,动态分区对数据分布不均匀的数据更适用。
分区的问题
对于选择通过多个分区做扩展的分布式数据库而言,有几个通用的问题需要解决,首先就是跨分区的一致性保证,大部分常用系统是通过 2PC 来解决分布式事务一致性问题,但是 2PC 在一些故障场景下,可能需要人工干涉才能解决,有些数据库甚至不提供一致性保证。其次就是跨分区的连接、聚合等操作等,有些数据库则提供了对部分算子的优化,其它算子则通过较低性能的解决方案用于解决多分区的连接,在这种情况下,需要应用侧权衡是否适用于当前业务。
数据路由
上面我们介绍了将大数据集拆分到不同分区的策略,但是如何将用户的数据操作请求发送到对应分区呢?随着数据的重新分布,分区对应的节点也会随之发生变化。一般情况下,分区的路由信息需要由某个组件进行维护,根据不同维护路由信息组件不同,我们可以将常见的路由方式分成如下四种:
- 协调节点路由:协调组件维护路由信息,如果有多个协调组件,每个组件都需要保存相同的分区信息,保证客户端连接到任意协调组件时都可以正确进行请求的路由。对于 SQL 分区数据库,可能需要在执行 DDL 操作时,需要将DDL 操作信息发送到其它所有的协调节点,客户端连接到其它 CN 时也可以正确对数据进行路由。
- 协调节点+源数据节点路由:元数据服务器保存路由信息,每次客户端从元数据服务器获取分区信息,或者订阅元数据信息,只要路由信息发生变化,则通知协调节点。例如 mongo
- 客户端路由:客户端直接访问分区数据,客户端保存了分区信息,客户端直接进行路由计算。例如 redis 的 cluster 集群
- 数据节点路由:分区节点直接提供路由支持,允许客户端连接任何分区。如果该节点恰巧拥有请求的分区,则它可以直接处理该请求;否则,它将请求转发到适当的节点,接收回复并传递给客户端。**例如 elasticsearch **
