Stack and a Heap ?
译者注:国内很多人对这两个词语的翻译总是让人糊涂的,这里译者统一做如下翻译,stack统一翻译为栈,而heap统一翻译为堆。
栈用于存储静态内存,堆用于动态内存分配,两者均存储在计算机的RAM中。
分配在栈上的变量直接存储到内存中,对该内存的访问也非常快,并且在程序编译时会处理它的分配。 当一个函数或方法调用另一个函数,然后又调用另一个函数等时,所有这些函数的执行将保持挂起状态,直到最后一个函数返回其值为止。 栈始终按LIFO顺序保留,最近保留的块始终是要释放的下一个块。 这使得跟踪栈真的非常简单,从栈中释放一个块只不过是调整一个指针而已(移动栈顶指针)。
在堆上分配的变量在运行时分配了内存,访问该内存的速度稍慢,但是堆大小仅受虚拟内存大小的限制。 堆的元素彼此之间没有依赖关系,并且始终可以随时随地进行随机访问。 您可以随时分配一个块,并随时释放它。 这使跟踪在任何给定时间分配或释放堆的哪些部分变得更加复杂。
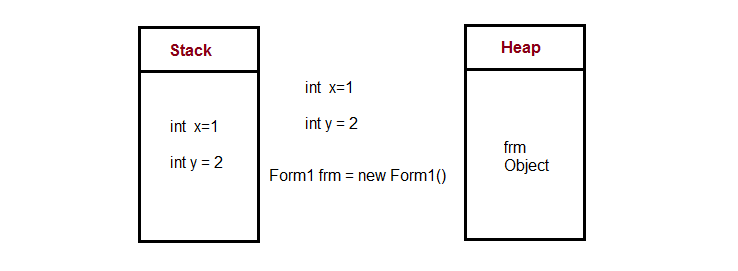
如果您确切知道在编译之前需要分配多少数据并且它不会太大,则可以使用栈。 如果您不知道运行时将需要多少数据,或者您知道需要分配大量数据,则可以使用堆。
在多线程情况下,每个线程将拥有其自己的完全独立的栈,但它们将共享堆。 栈是特定于线程的(译者注:这里译者理解为线程私有),而堆是特定于应用程序的(译者注:这里译者理解为进程私有)。 在异常处理和线程执行中,必须考虑栈。
原文链接:http://net-informations.com/faq/net/stack-heap.htm
扩展内存分配的类型
静态内存分配
静态分配是指在程序启动时分配变量的内存。 创建程序时大小是固定的。 它适用于全局变量,文件范围变量以及在内部函数中定义为静态的合格变量。
分配位置:数据段(data segment),BSS段
生命周期:整个程序的声明周期
NOTE
说静态内存是在编译时分配的,这有点令人困惑,尤其是如果我们开始考虑编译机和主机可能不相同,甚至可能不在同一体系结构上时。
最好认为静态内存的分配是由编译器处理的,而不是在编译时进行分配。
例如,编译器可能会在已编译的二进制文件中创建一个较大的数据段(data segment),并且当程序加载到内存中时,程序数据段内的地址将用作分配内存的位置。这具有明显的缺点,如果使用大量静态内存,则使已编译的二进制文件非常大。可以编写由不到六行代码生成的数千兆字节的二进制文件。编译器的另一种选择是在执行程序之前注入分配内存的初始化代码。该代码将根据目标平台和操作系统而有所不同。实际上,现代编译器使用启发式方法来决定使用这些选项中的哪个。您可以编写一个小的C程序来自己尝试一下,该程序为10k,1m,10m,100m,1G或10G项分配一个大型静态数组。对于许多编译器,二进制大小将随着数组的大小线性增长,并且超过一定点后,由于编译器使用另一种分配策略,二进制大小将再次缩小。
自动内存分配
自动内存分配发生在函数内部定义的(非静态)变量上,并且通常存储在栈中(尽管C标准并不要求使用栈)。 使用这些变量时,您不必保留额外的内存,但是,另一方面,对这些内存的生存期的控制也很有限。 例如:函数中的自动变量仅在函数完成之前存在。
分配位置:栈
生命周期:scope
动态内存分配
动态内存分配有些不同。 现在,您可以控制这些内存位置的确切大小和生存期。 如果不释放它,则会遇到内存泄漏,这可能会导致您的应用程序崩溃,因为在某些时候,系统无法分配更多的内存。
1 | int* func() { |
在上例中,即使函数终止,分配的内存仍然有效且可访问。 内存用完后,您必须释放它:
1 | free(mem); |
分配位置:堆, 栈
生命周期:主动释放