[toc]
常见的执行速度
1 | 1. 内网 ping 时间(阿里云内网) |
计算存储体系结构
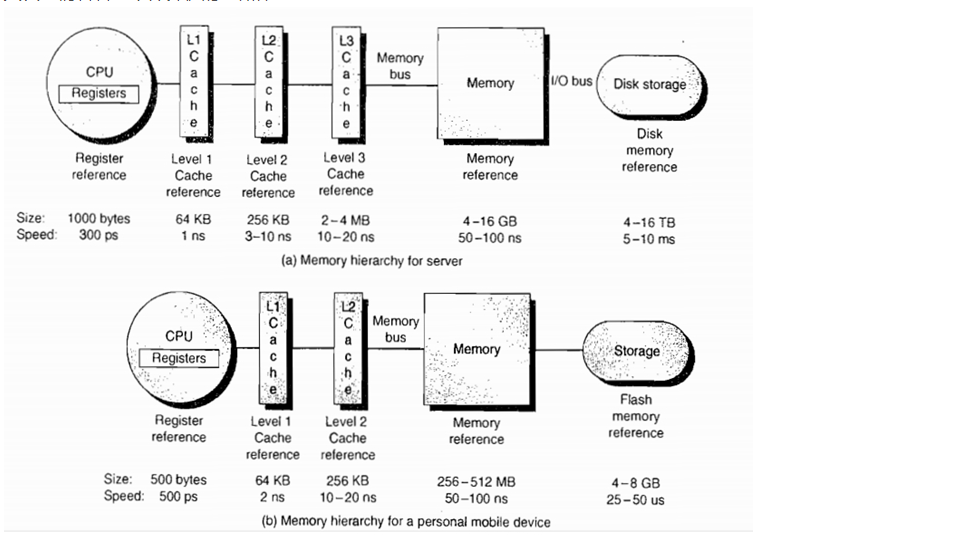
计算存储速度
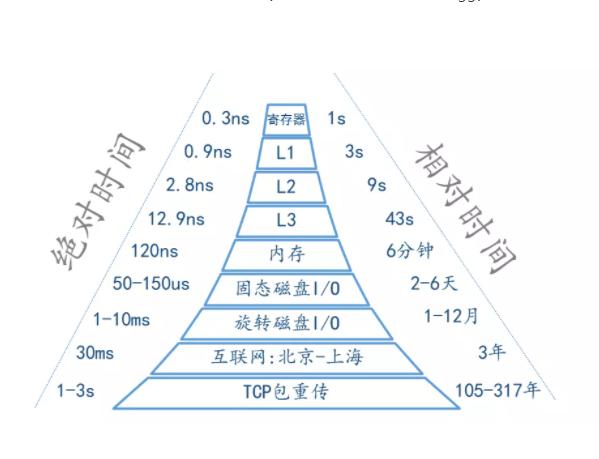
CPU眼中的时间
CPU绝对称得上是“闪电侠”,因为它们做事都有自己的一套时钟。我们故事的主人公是一个主频为2.5GHz的CPU,如果它的世界也有“秒”的概念,并且它的时钟跳一下为一秒,那么在CPU(CPU的一个核心)眼中的时间概念是啥样的呢?
CPU先生所在的组是硬件部计算组。对它来说,与其一起紧密合作的几个小伙伴还能跟的上它的节奏:
CPU先生很利索,只需要一秒就可以完成一个指令,复杂的动作可能需要多个指令。
好在“贴身秘书”一级缓存反应比较快,能够秒懂CPU先生的意思。
来自“秘书组”的二级缓存虽然要十几秒才能“get”到CPU先生的点,但也不算太迟钝。
和内存组的合作已经习以为常了,跟内存请求的数据通常要4-5分钟才能找到(内存寻址),不过也还好啦,毕竟一级缓存那里能拿到80%想要的数据,其余的二级缓存也能搞定一大部分,不怎么耽误事儿。
CPU先生是典型的工作狂,任务多的时候,通宵达旦也毫无怨言,但是有什么事情让它等,那简直要他命了。恰恰一起共事的其他组(尤其是I/O组的磁盘和网卡)相对来说那效率是低的离谱啊:
关于I/O组的同事,CPU先生已经抱怨很久了,每次找SSD要东西,都要花费4-5天才能找到(寻址),等到数据传送过来,几周都过去了。机械磁盘更是过分地离谱,跟他要个数据,竟然要平均花费10个月才能找到,如果要读取1M的数据,竟然要20个月!这种员工怎么还不下岗?!
关于网卡,CPU先生知道它们也尽力了,毕竟万兆网络成本颇高。与机房内的其他小伙伴们用千兆网络互相沟通也算顺畅,给另一台机器的CPU朋友发送1K的书信,最快七八个小时就可以送过去了。但是1K的书信经过层层包裹,实际也写不了多少话。更要命的是,网卡们的沟通手续繁杂,每次网络沟通前的 “你好能听到我吗?——我能听到,你那边能听到我吗?——我也能听到你,那我们开始吧!” 这样的握手确认都要花掉很长的时间,不过不能当面沟通,也只能这样了。这还好,最恐怖的是与其他城市的小伙伴沟通,有时候传递消息要花费好几年呢!